[LG]《Tracing the Representation Geometry of Language Models from Pretraining to Post-training》M Z Li, K K Agrawal, A Ghosh, K K Teru... [McGill University & UC Berkeley] (2025)
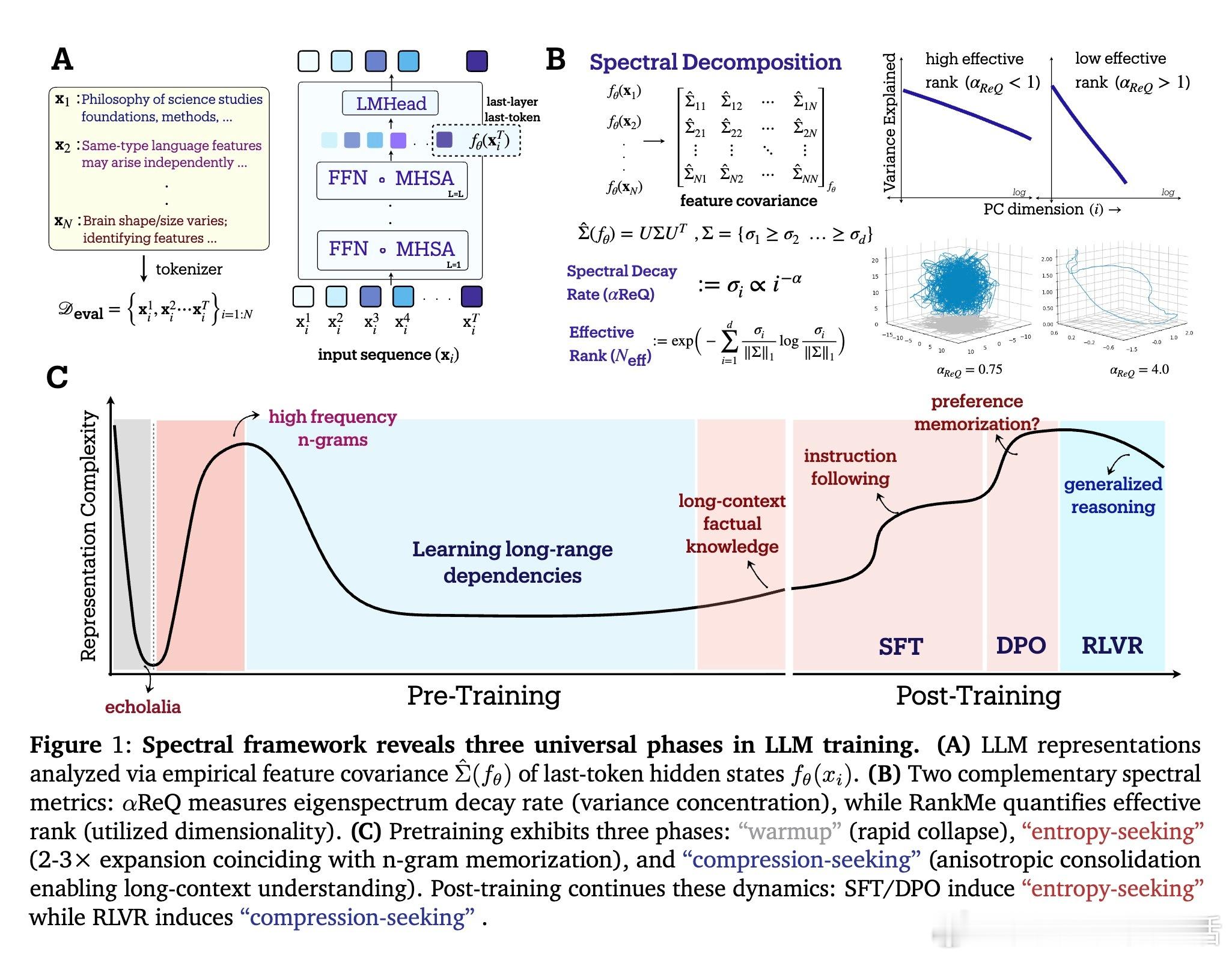
大型语言模型的训练过程远非单调,内部表征空间经历三大几何阶段,揭示记忆与泛化的本质差异:
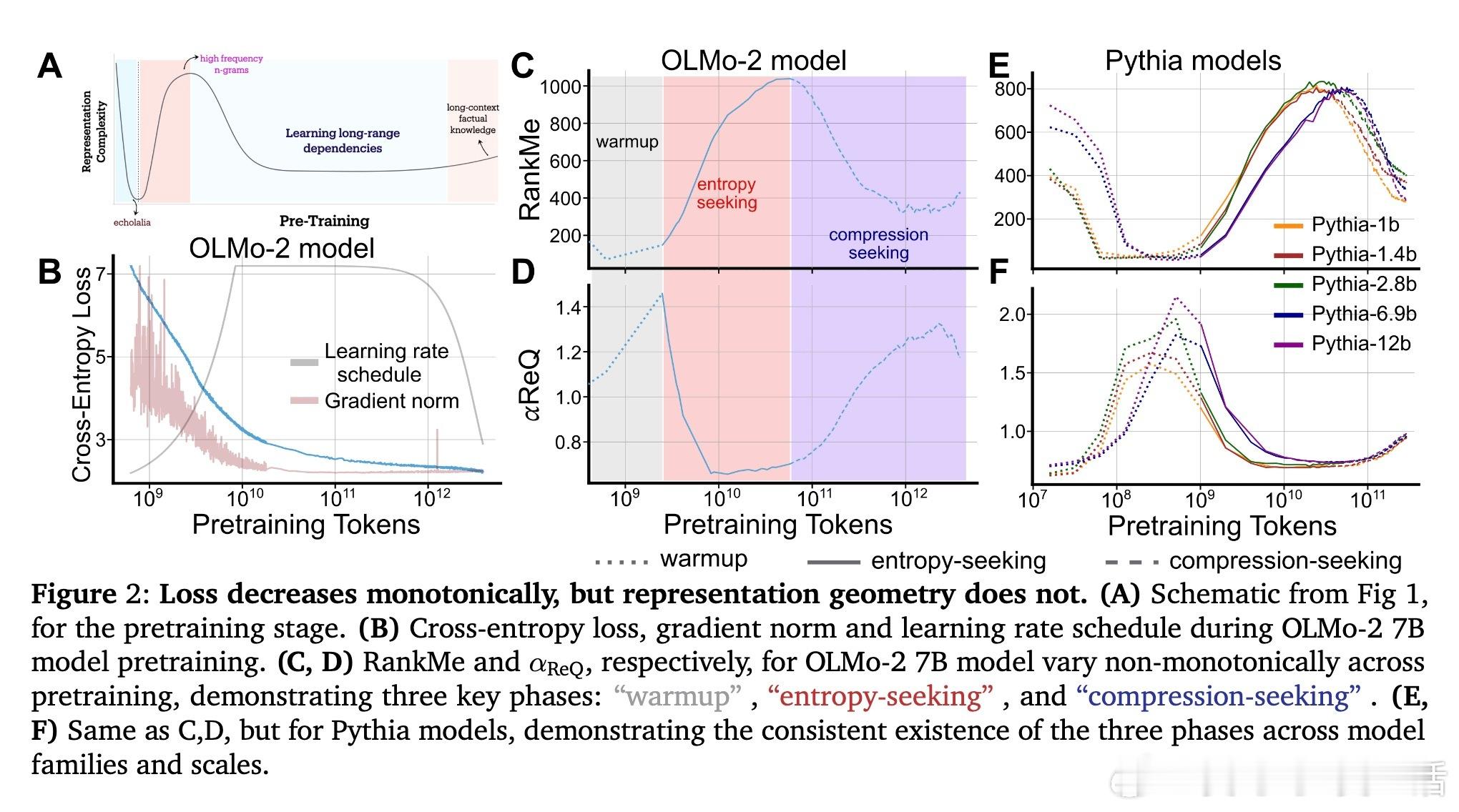
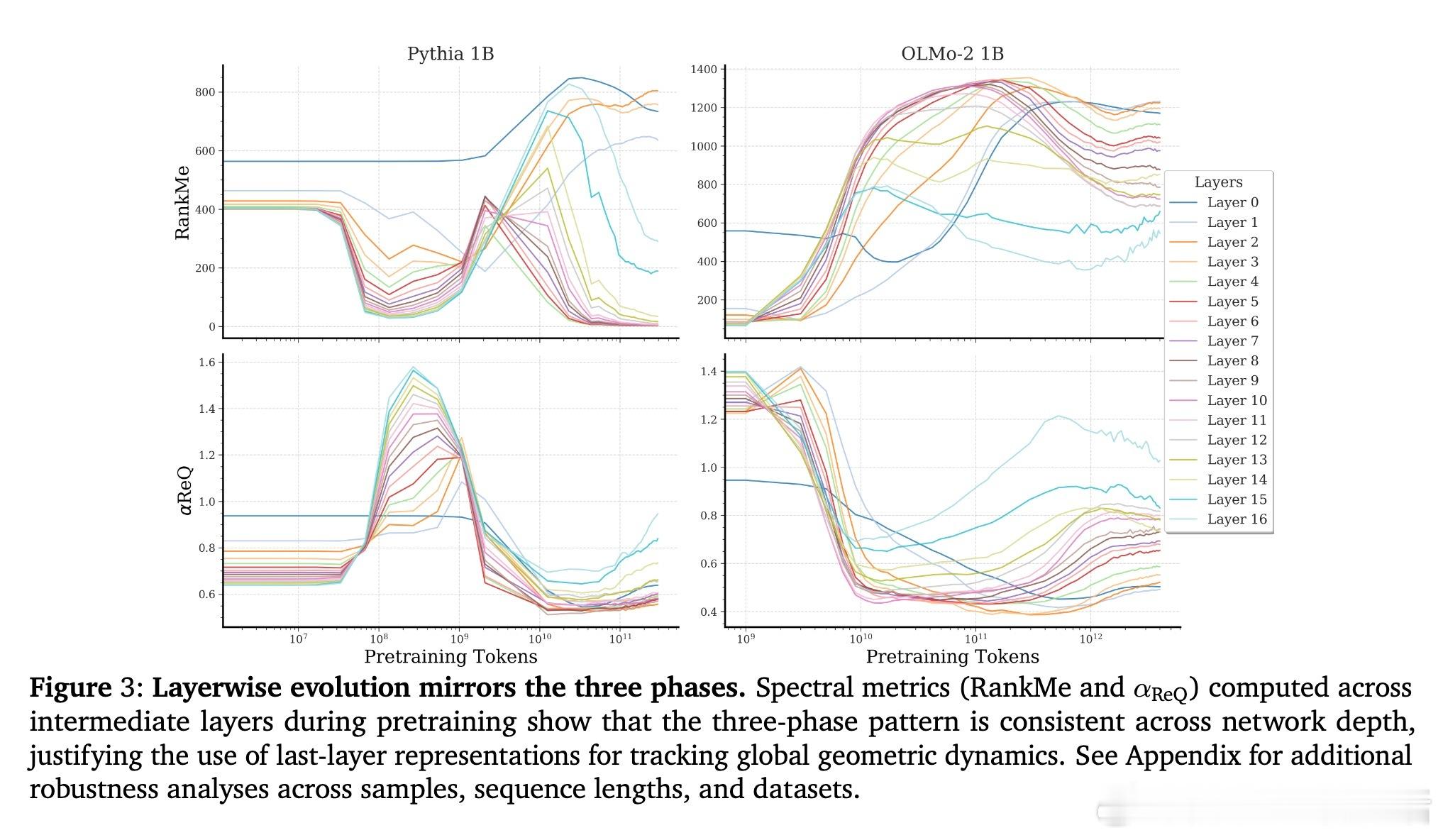
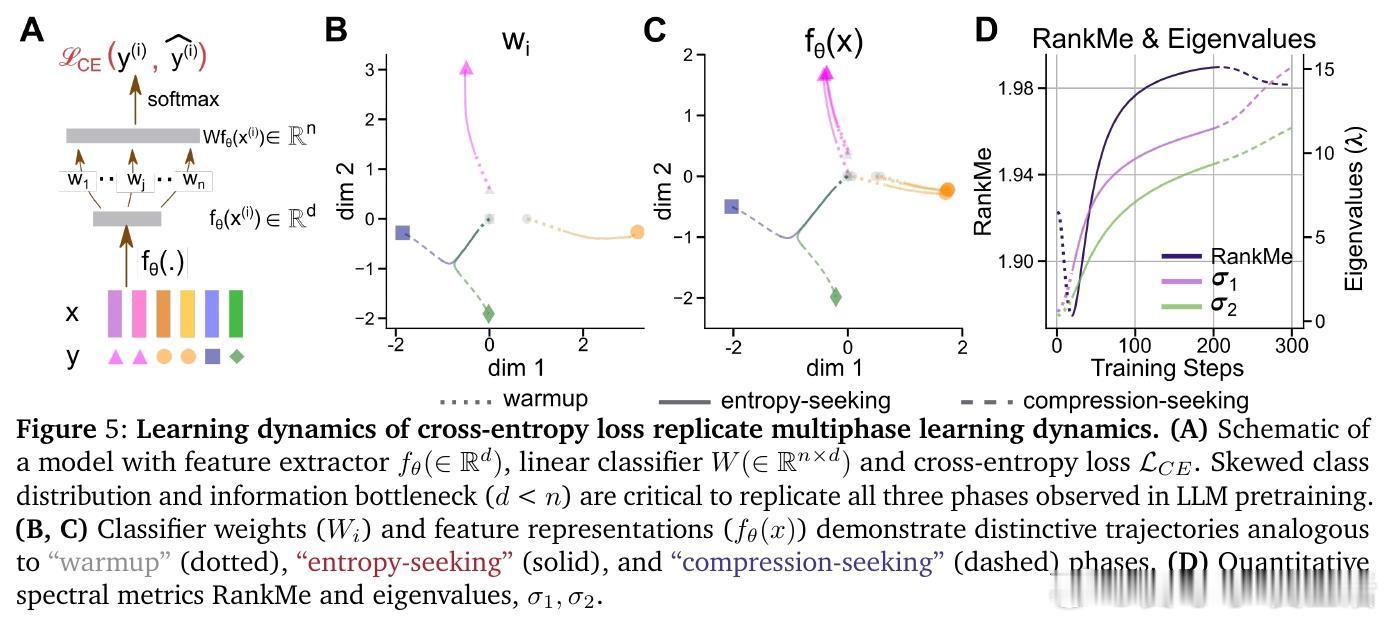
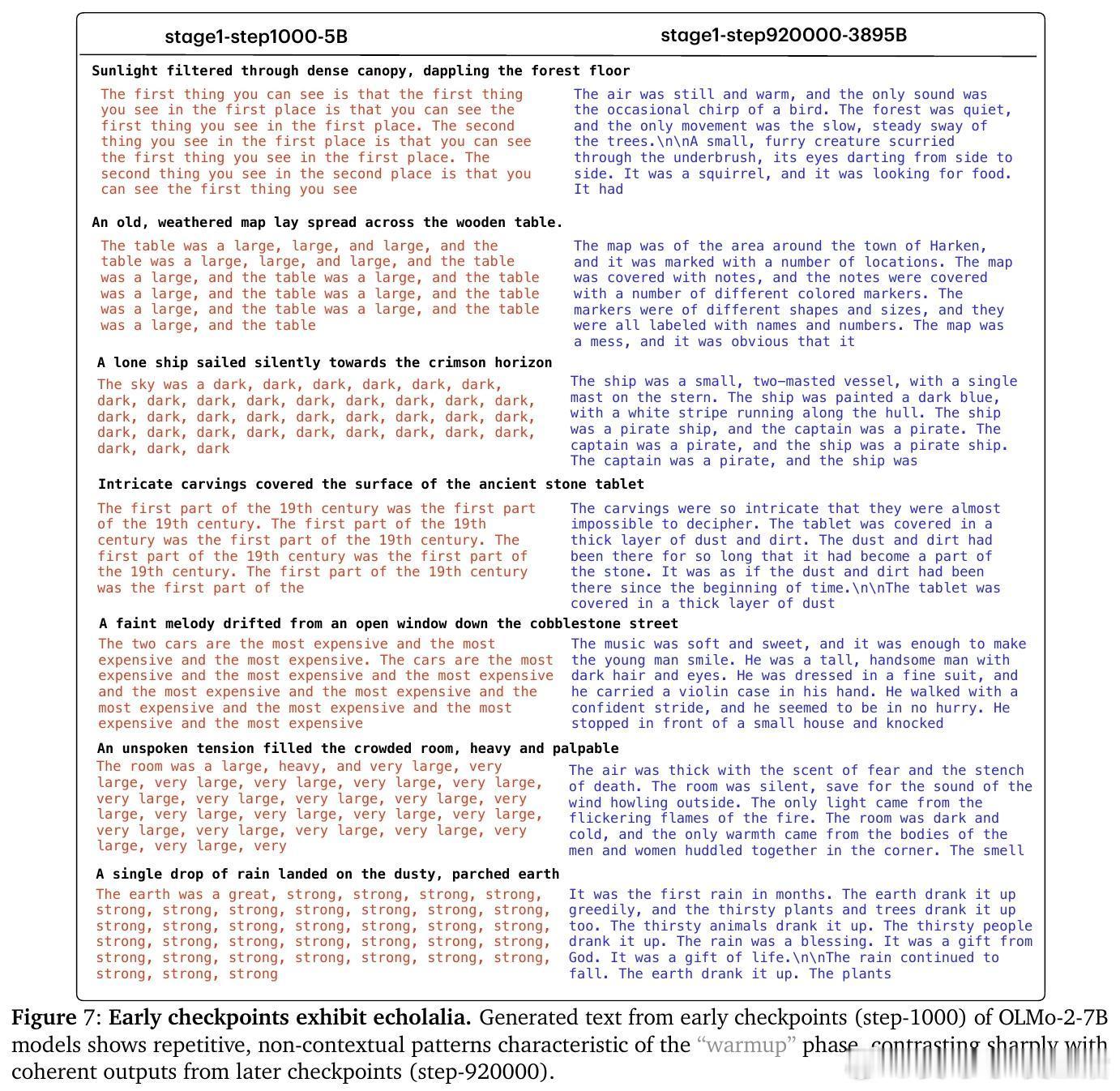
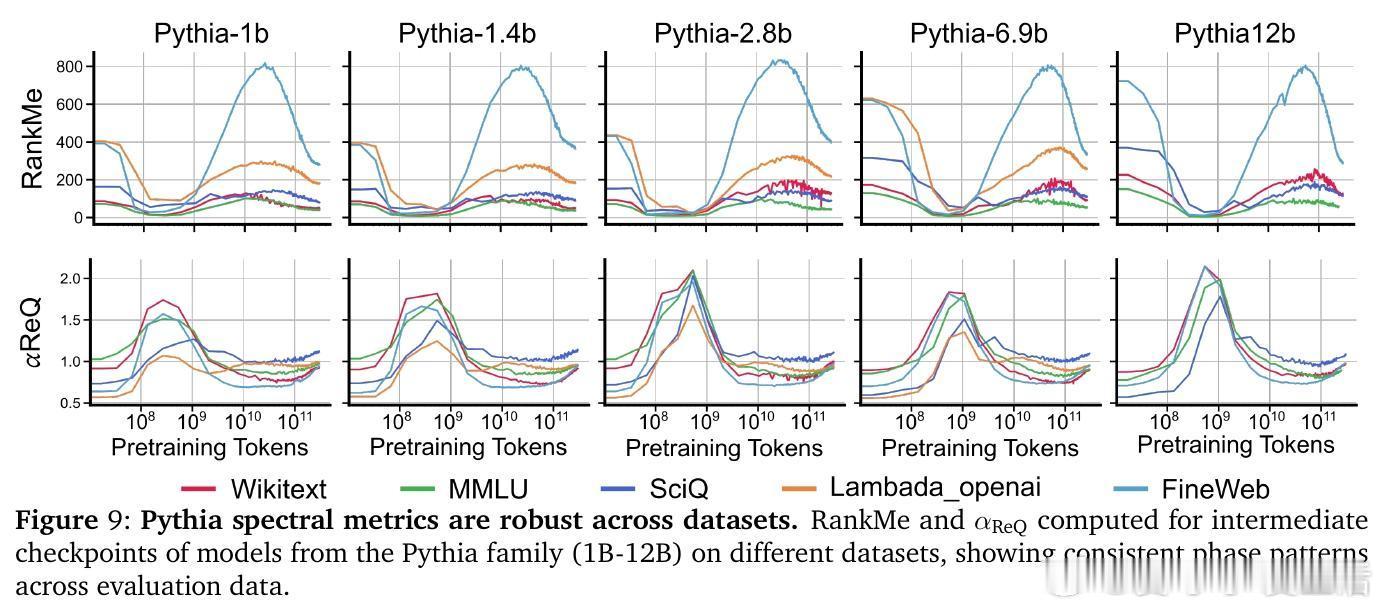
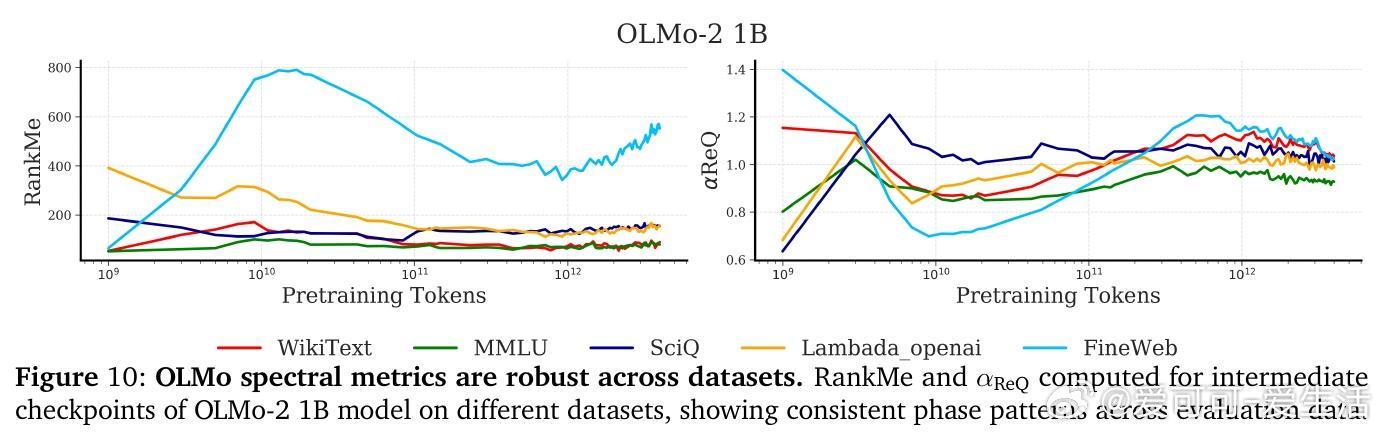
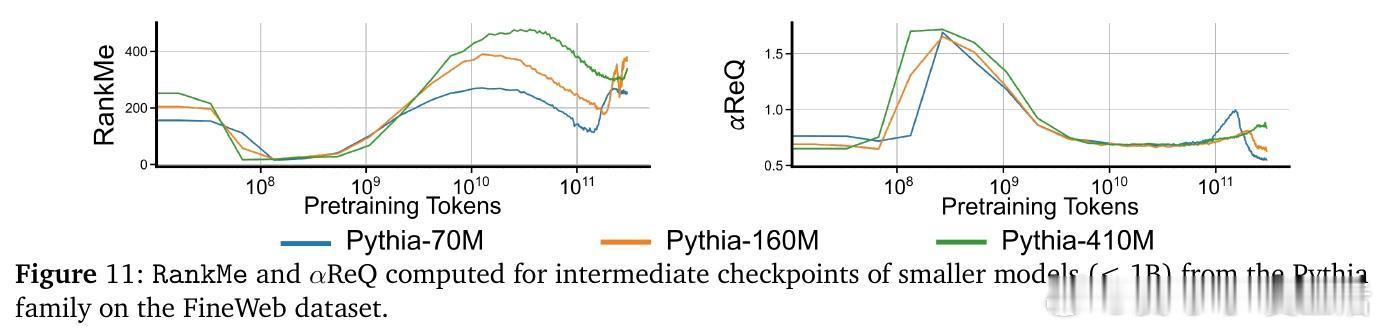
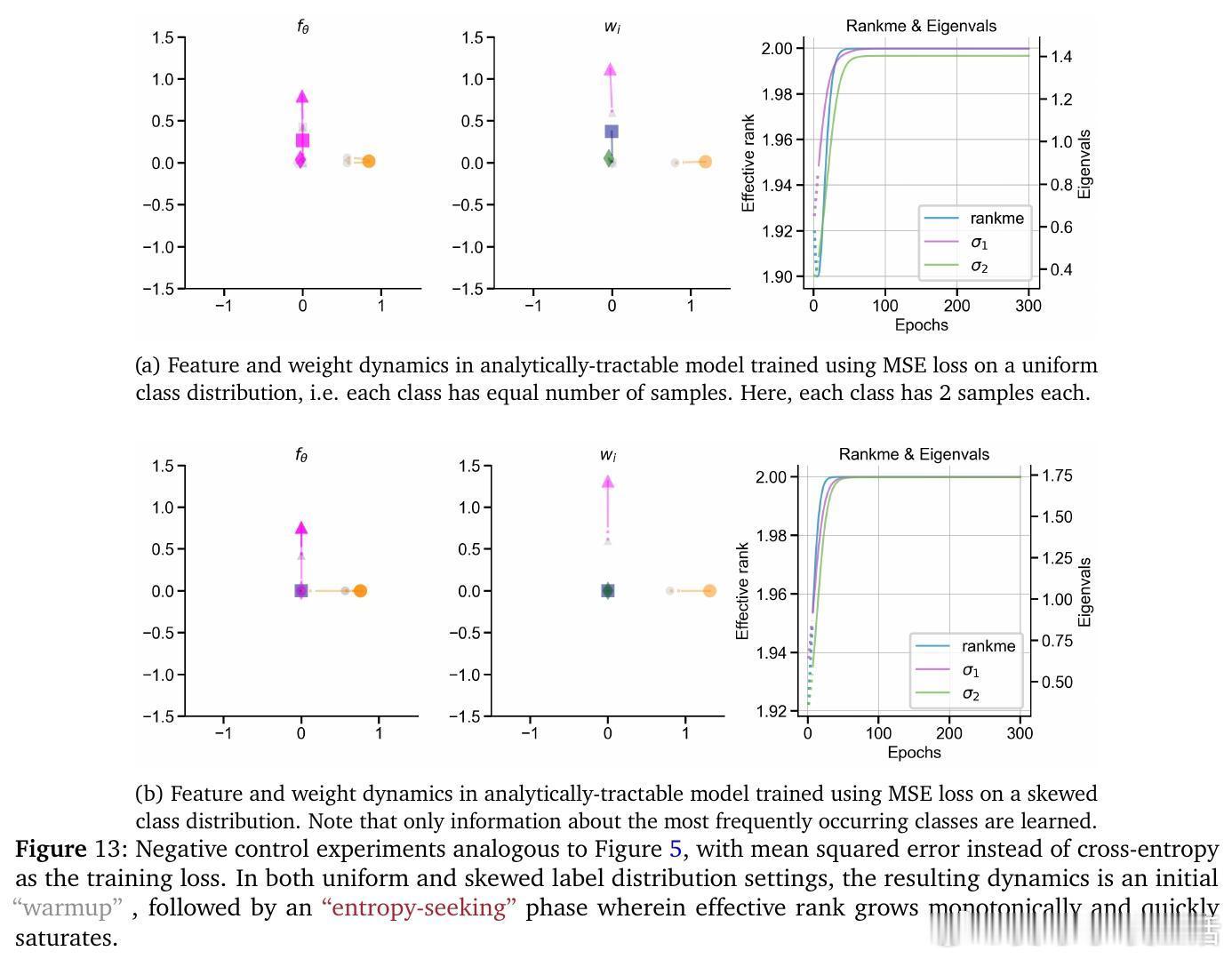
• 预训练阶段呈现非单调演变:初期“warmup”阶段快速坍缩表征维度,随后“entropy-seeking”阶段有效维度激增(RankMe↑,α_ReQ↓),对应于高峰的n-gram分布记忆,最后“compression-seeking”阶段通过各向异性压缩(RankMe↓,α_ReQ↑)强化主导特征方向,推动长上下文理解和泛化能力提升。
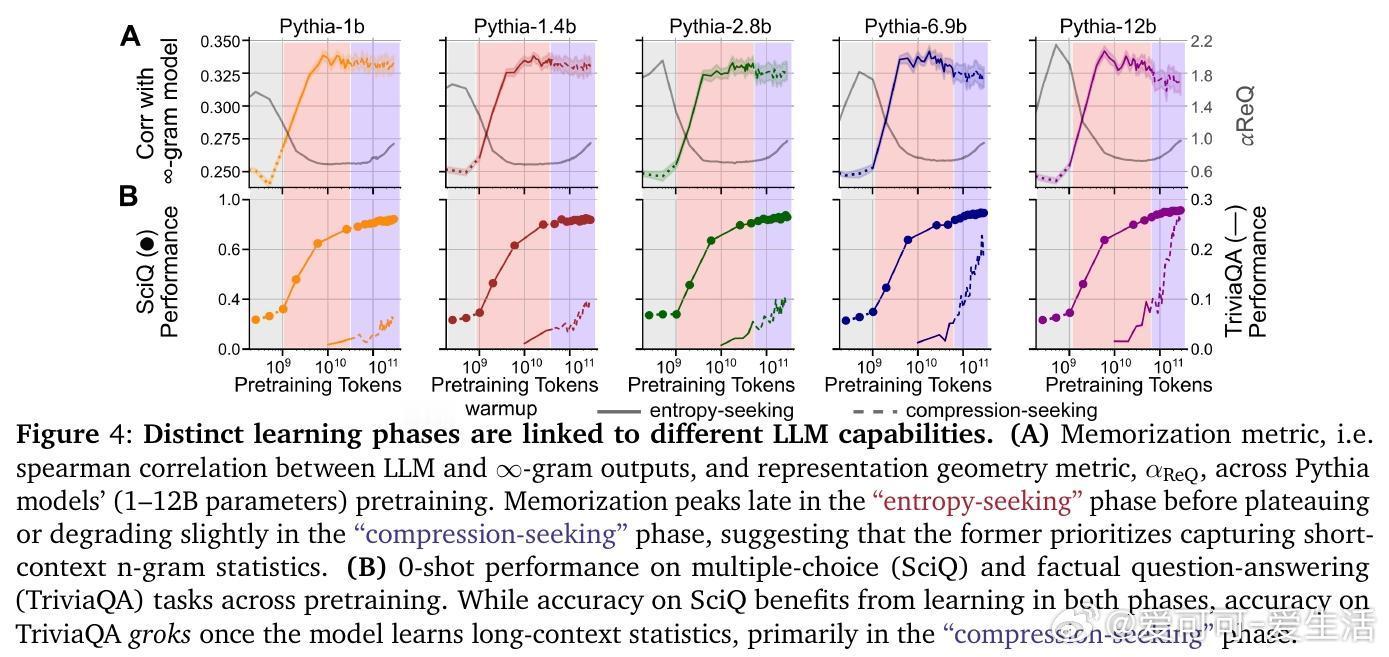
• 记忆与泛化解耦:短上下文模式主要在“entropy-seeking”阶段学习,表现为对训练数据的分布式记忆;而长上下文推理能力则在“compression-seeking”阶段显著提升,任务准确率伴随表征几何的各向异性整合而跃升。
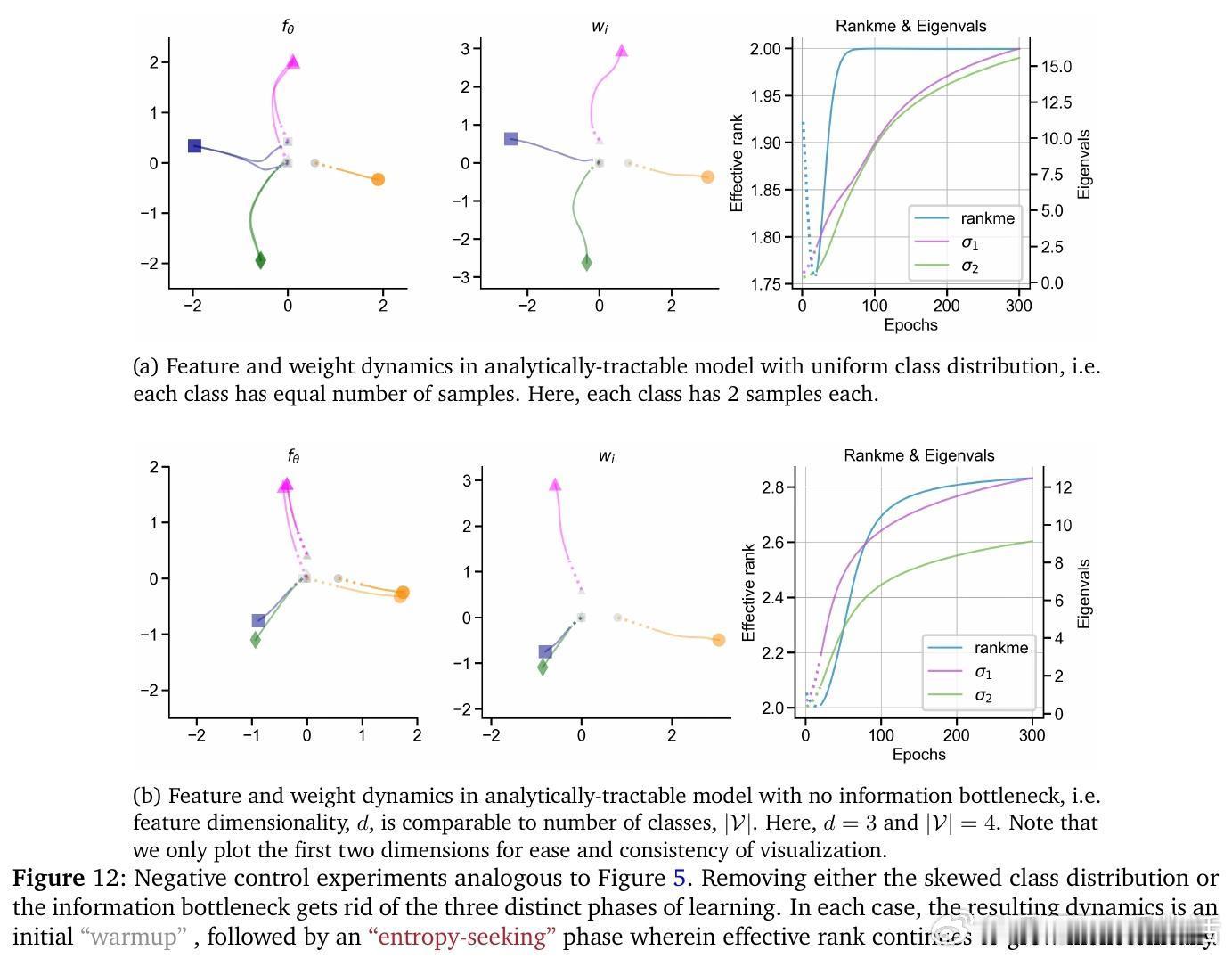
• 优化机制驱动多阶段动力学:基于交叉熵的梯度下降在高频词汇优先学习(primacy bias)和表征瓶颈限制下,促成表征空间的先扩张后压缩。消除词频不均或瓶颈结构会丧失这一多相学习轨迹。
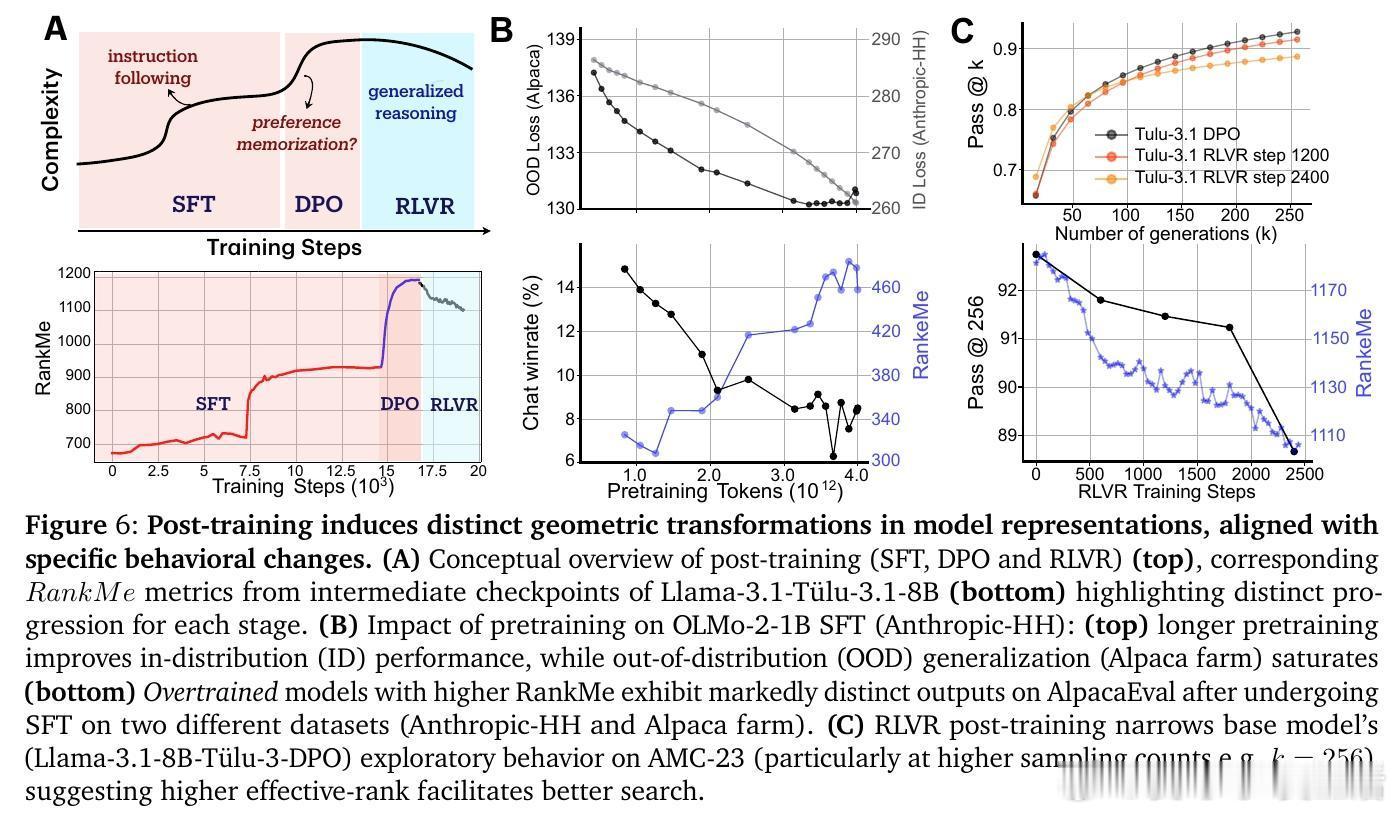
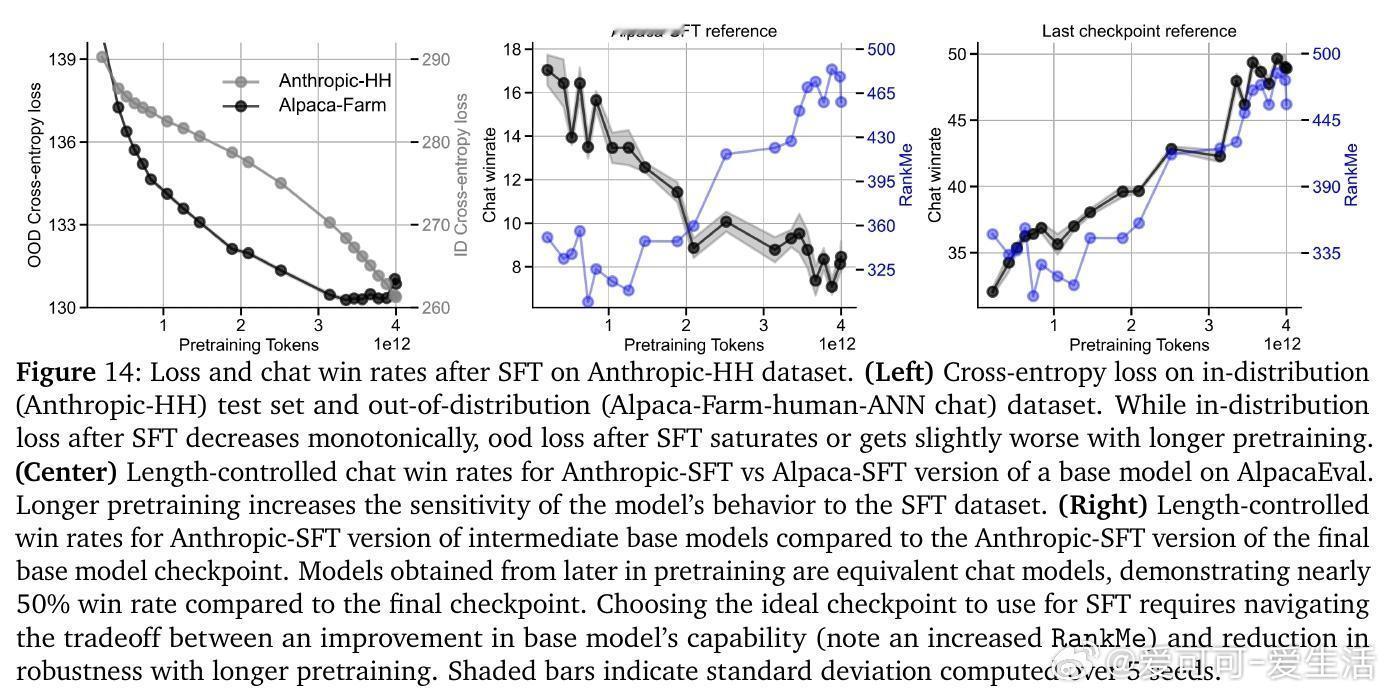
• 后训练细化表征几何:监督微调(SFT)与直接偏好优化(DPO)延续“entropy-seeking”,扩展表征复杂度,提升内部分布性能但削弱外部分布鲁棒性;强化学习奖励优化(RLVR)则表现为“compression-seeking”,增强奖励对齐但限制生成多样性。
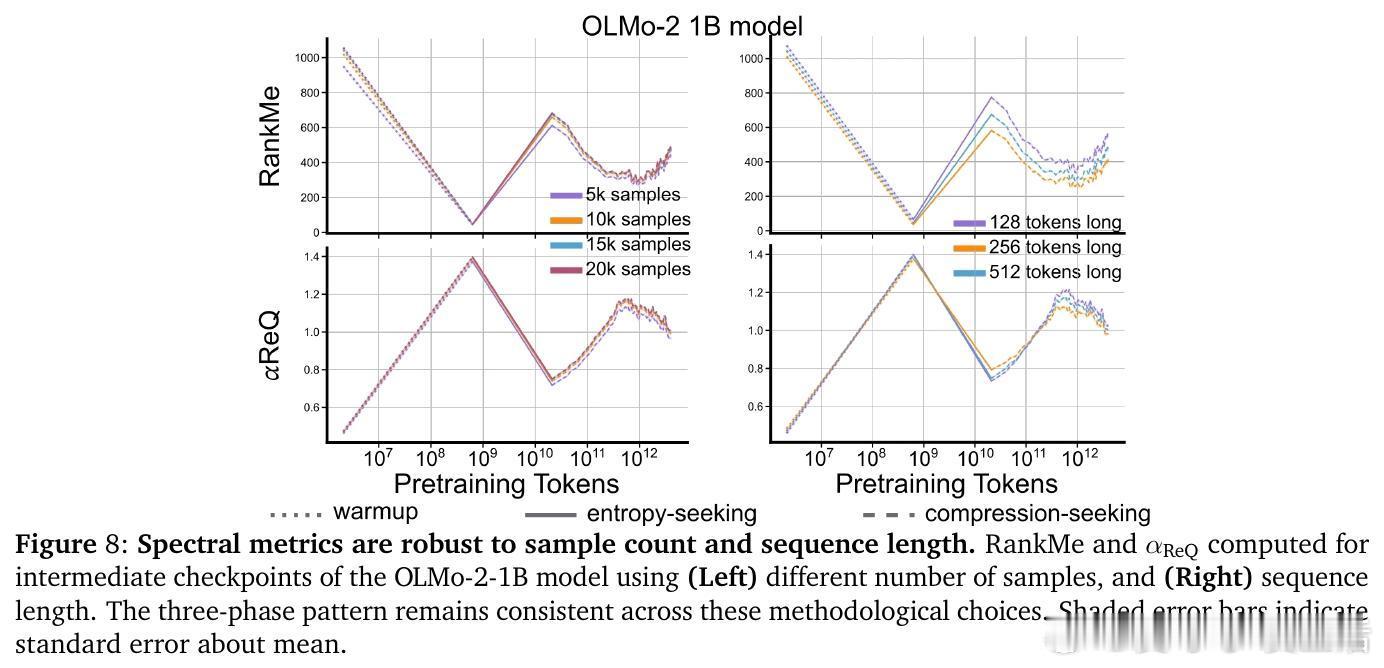
• 有效维度测度RankMe和谱衰减指数α_ReQ涵盖完整特征谱信息,保留全部谱信息对下游任务性能至关重要,剔除主成分严重损害能力,强调语言理解依赖于复杂分布的全谱表征。
心得:
1. 训练损失单调下降掩盖了表征空间深刻的几何演变,理解模型能力跃迁需从高维谱结构视角入手。
2. 记忆与泛化不仅表现不同,且对应于表征空间的截然不同几何阶段,提示训练策略可针对性调控表征复杂度。
3. 后训练阶段的几何变换映射到能力权衡,提醒我们在微调和强化学习中需平衡拟合效果与泛化鲁棒性。
深入了解这套谱分析框架,有助于优化大模型训练与适应策略,推动更高效的能力培养。
详情🔗 arxiv.org/abs/2509.23024
大型语言模型表征几何预训练谱分析机器学习优化模型泛化