Anthropic祭出最强编程Claude4.5Claude4.5连续写代码30小时
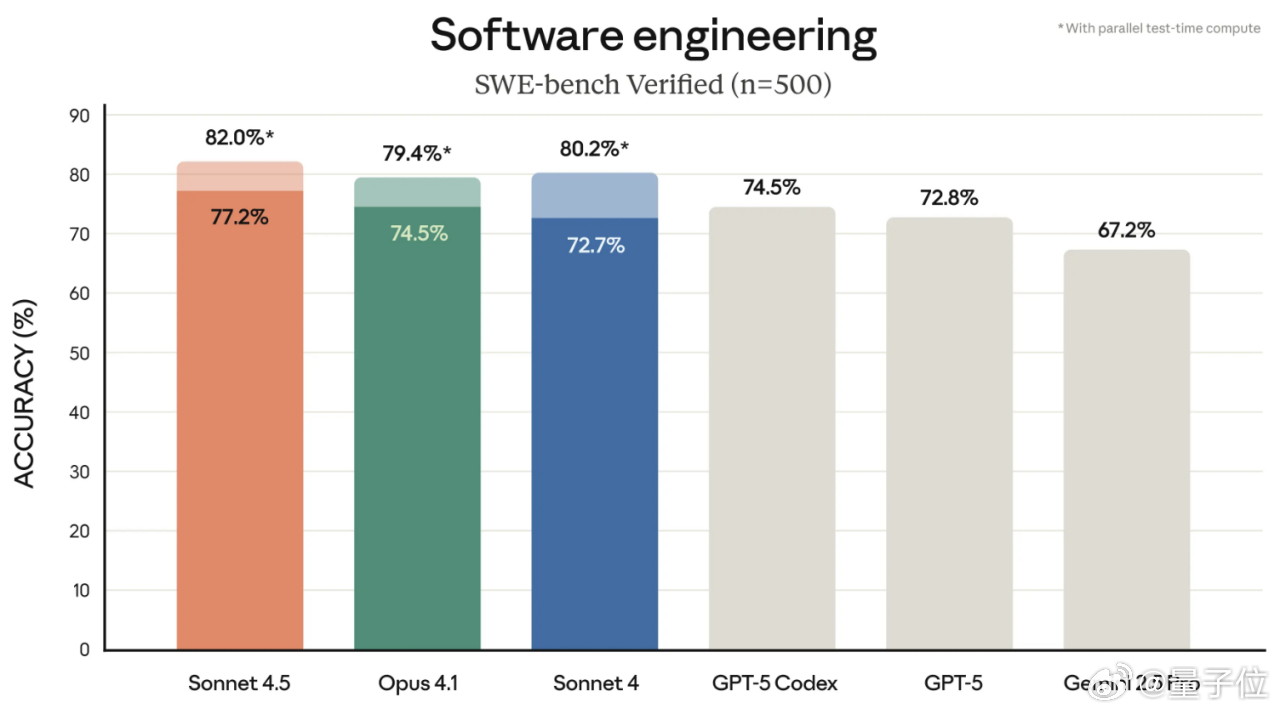
最强编程模型让位了!新发布的Claude Sonnet 4.5,在SWE-bench上的成绩比Sonnet 4提升了1.8个百分点,而且提质不加价。【图1】
而且有第三方表示,Claude Sonnet 4.5能一口气工作30个小时,完全自主地编写代码。
在这30个小时里,Claude Sonnet 4.5写了11000多行代码,构建出了类似Slack的聊天应用。【图2】
此前Opus 4曾因为连续工作7小时就备受关注,现在这个数字直接变成了4倍多。
计算机操作方面,Claude Sonnet 4.5在OSWorld测试中取得了60.2分的SOTA成绩,比Sonnet 4提升了近一半。
总之,Claude Sonnet 4.5在多项领域都实现了对自己的超越,成为该领域内的最佳模型。
先有昨晚的DeepSeek-V3.2,紧接着又是Claude Sonnet 4.5,赶在节前密集上新的模型,看来是真的不让人放假了。(手动狗头)
来看Anthropic晒出的Claude Sonnet 4.5成绩单。
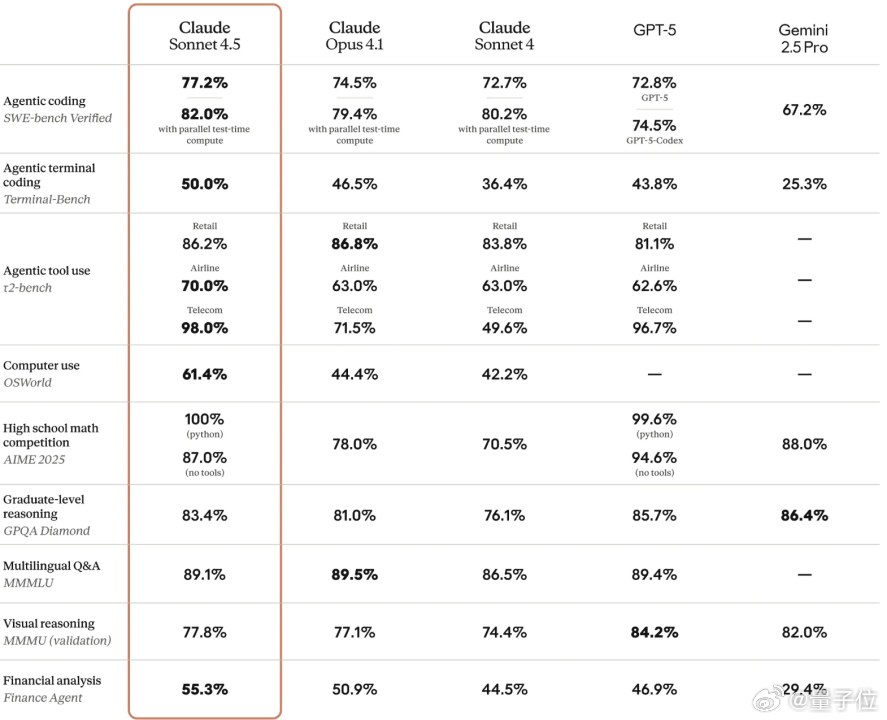
除了已经介绍过的Swe-bench和OSWorld之外,Claude Sonnet 4.5也在终端编程(Terminal-Bench)、工具使用(τ2-bench)等测试集中取得长足进步。
在高中水平的数学方面,AIME 2025试题中,如果借助Python,Claude Sonnet 4.5可以做到100%的准确率,不借助任何工具也能达到87%。【图3】
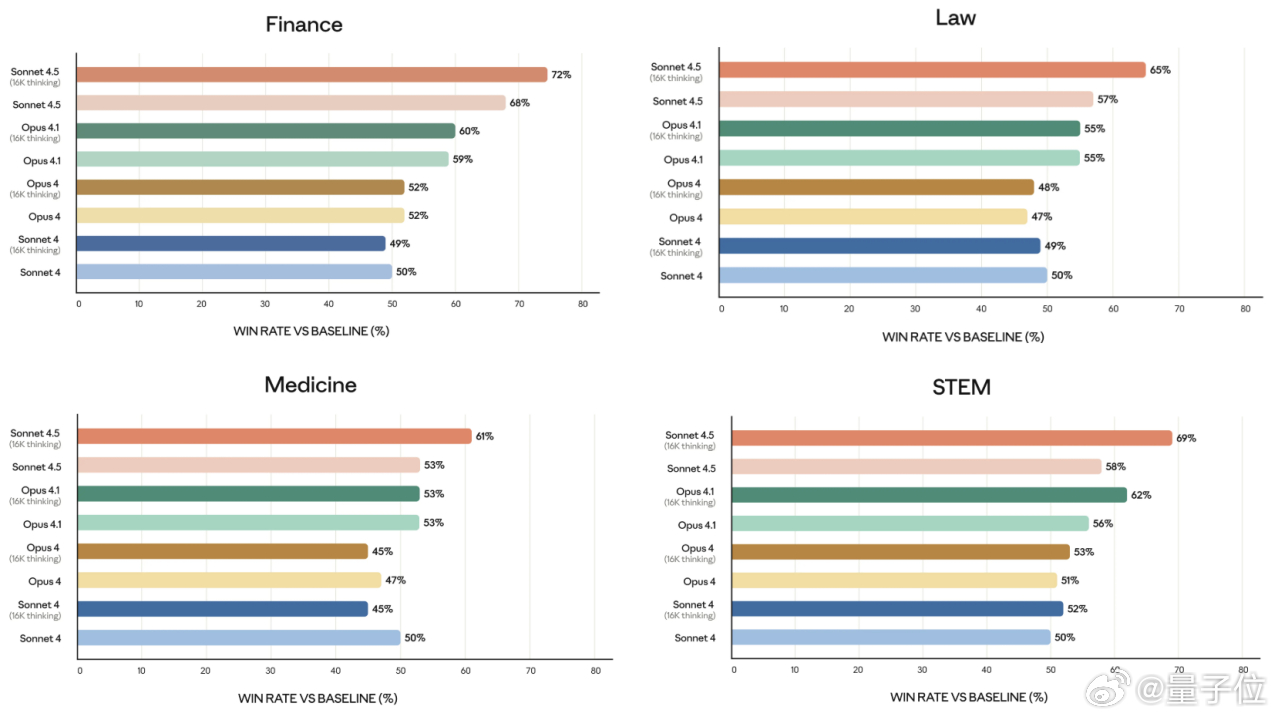
另外,Anthropic还专门展示了Claude Sonnet 4.5在金融、医疗、法律以及STEM等专业领域的表现。
在这四个领域当中,Claude Sonnet 4.5相比Sonnet 4,对战baseline模型的胜率均有大幅度提升,且在16K上下文、开启思考的情况下,均超过60%。【图4】
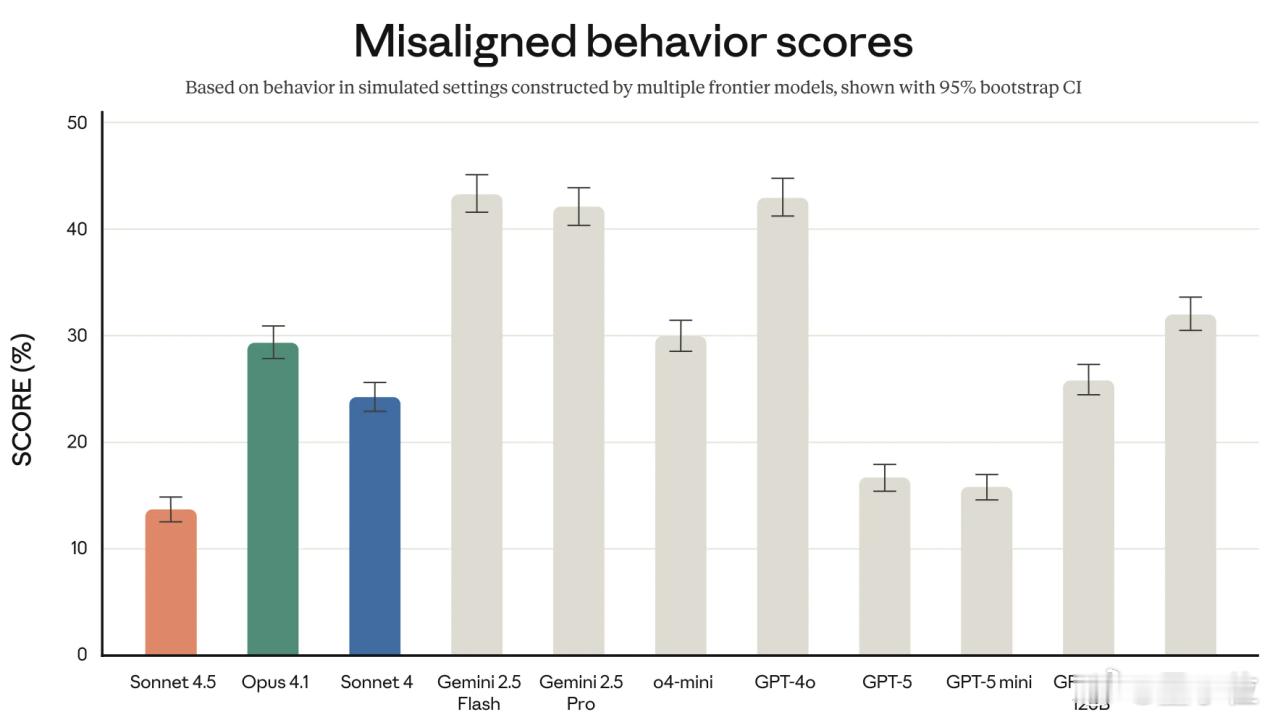
除了以上各种性能,Anthropic还重点强调了Claude Sonnet 4.5的对齐和安全性指标。
通过安全训练,Anthropic减少了Claude Sonnet 4.5的谄媚、欺骗等不良行为;在智能体和计算机场景下,Claude Sonnet 4.5在防御即时注入攻击方面也取得了显著进展。
同时,针对正常内容的误报也有所降低,正常请求拒绝率从Sonnet 4时的0.15%下降到了0.02%。【图5】
Claude Sonnet 4.5的表现,获得了众多第三方的高度评价。
GitHub首席产品官Mario Rodriguez表示,Claude Sonnet 4.5让GitHub Copilot能更好地处理复杂的跨代码库任务。【图6】
Cognition联创兼CEO Scott Wu也表示,Claude Sonnet 4.5让Devin的规划能力和端到端评估成绩大幅度提升。【图7】
非编程类任务当中,也有金融机构的人工智能主管表示Claude Sonnet 4.5能够提供投资级的洞察。【图8】
最后说价格,Claude Sonnet 4.5提质不加价,与Sonnet 4保持一致,为3美元每百万输入token,15美元每百万输出token。