[CL]《Beyond the Leaderboard: Understanding Performance Disparities in Large Language Models via Model Diffing》S Boughorbel, F Dalvi, N Durrani, M Hawasly [HBKU] (2025)
SimPO微调如何改变Gemma-2-9b模型表现?本文用模型diffing深入解码LLM微调背后的能力变迁,超越排行榜分数直观比较。
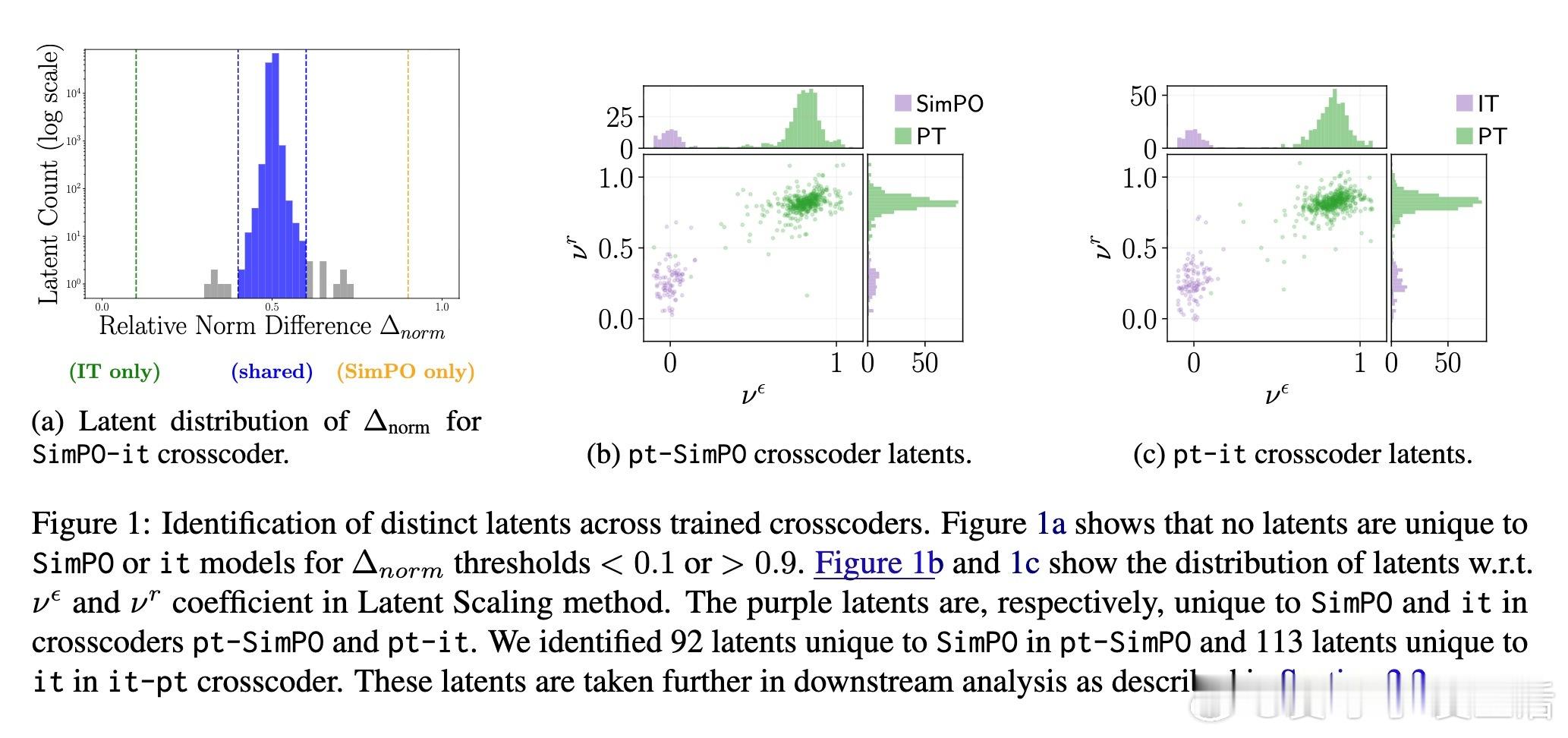
• 采用crosscoders对Gemma-2-9b-it与SimPO微调版本进行潜在空间差异分析,识别92个SimPO独有latent,113个it独有latent。
• SimPO显著提升安全内容过滤(+32.8%)、多语言处理(+43.8%)和指令遵循能力(+151.7%),强化了对人类偏好的对齐与响应风格优化。
• 但同时牺牲了模型自我引用(-44.1%)、幻觉检测(-68.5%)、结构化输出与代码生成等技术能力,显示出流畅性与内省性的权衡。
• 传统benchmark和人类评测难以揭示这些细微能力迁移,模型diffing为理解微调带来的具体行为改变提供了全新视角。
• 研究还扩展至DPO微调,证明该方法可广泛适用不同训练策略,揭示细节与趋势差异,支持更透明、细粒度的LLM性能诊断。
心得:
1. 微调不仅是性能提升,更是能力结构的重塑,表面分数提升可能掩盖核心能力倒退。
2. 安全与风格优化往往伴随推理与验证能力下降,提示设计微调策略需权衡多维目标。
3. 细粒度潜在空间分析为模型开发者提供了超越黑盒的行为理解工具,有助于精准改进与风险评估。
了解更多🔗 arxiv.org/abs/2509.18792
大语言模型模型解释微调分析人工智能安全多语言处理模型性能