[LG]《Bootstrapping Task Spaces for Self-Improvement》M Jiang, A Lupu, Y Bachrach [Meta Superintelligence Labs] (2025)
探索式迭代(ExIt):用单步训练驱动多步推理自我提升的强化学习新范式
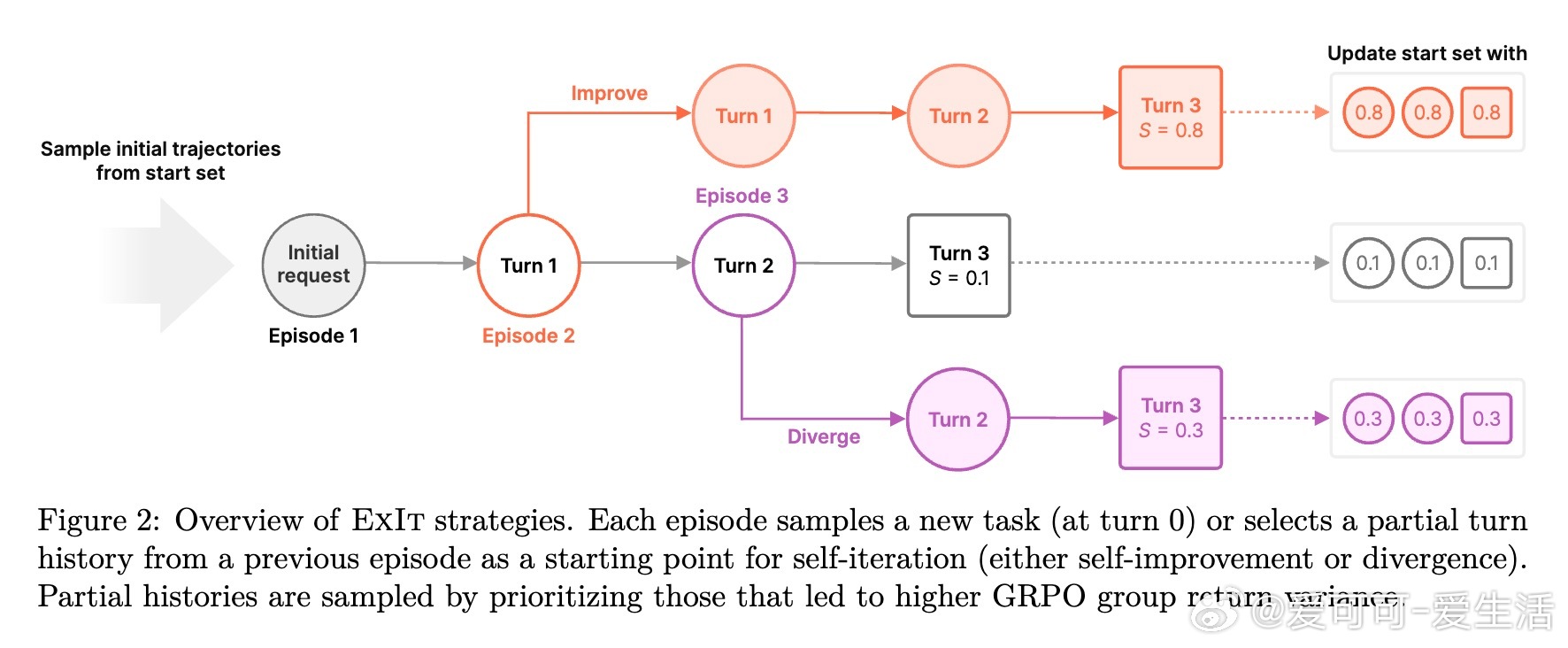
• 解决传统多步自我提升训练成本高及深度限制问题,ExIt通过优先采样最具学习潜力的中间历史,构建开放任务空间。
• 仅用单步自我提升任务训练,动态生成多步迭代链,实现推理时超过训练深度的自我优化。
• 引入探索机制(ϵ-贪婪自我发散、基于嵌入空间多样性加权),有效提升任务多样性,防止RL训练陷入单一解法。
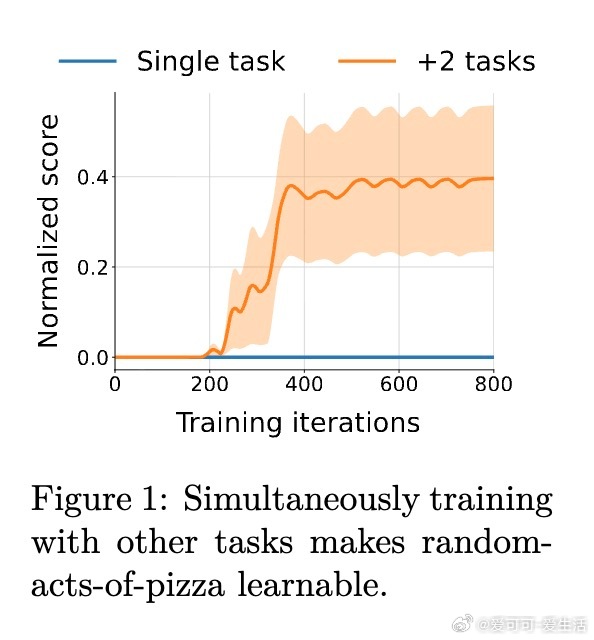
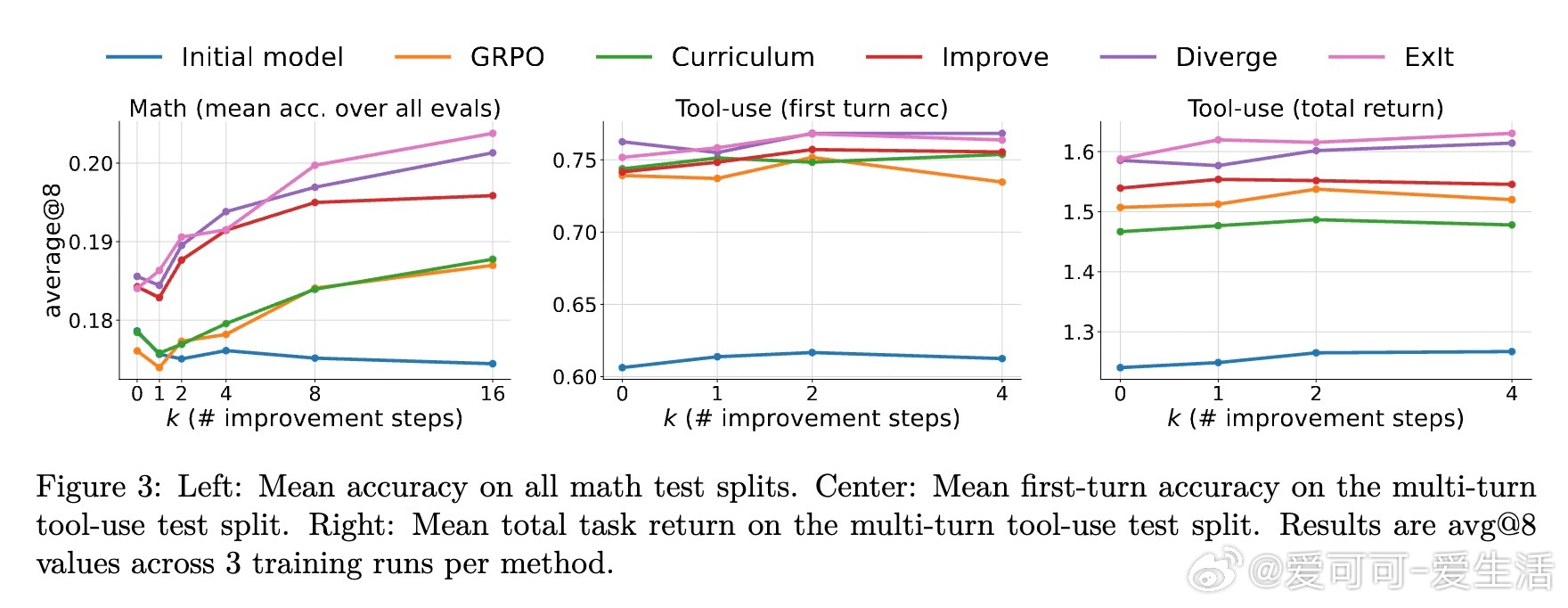
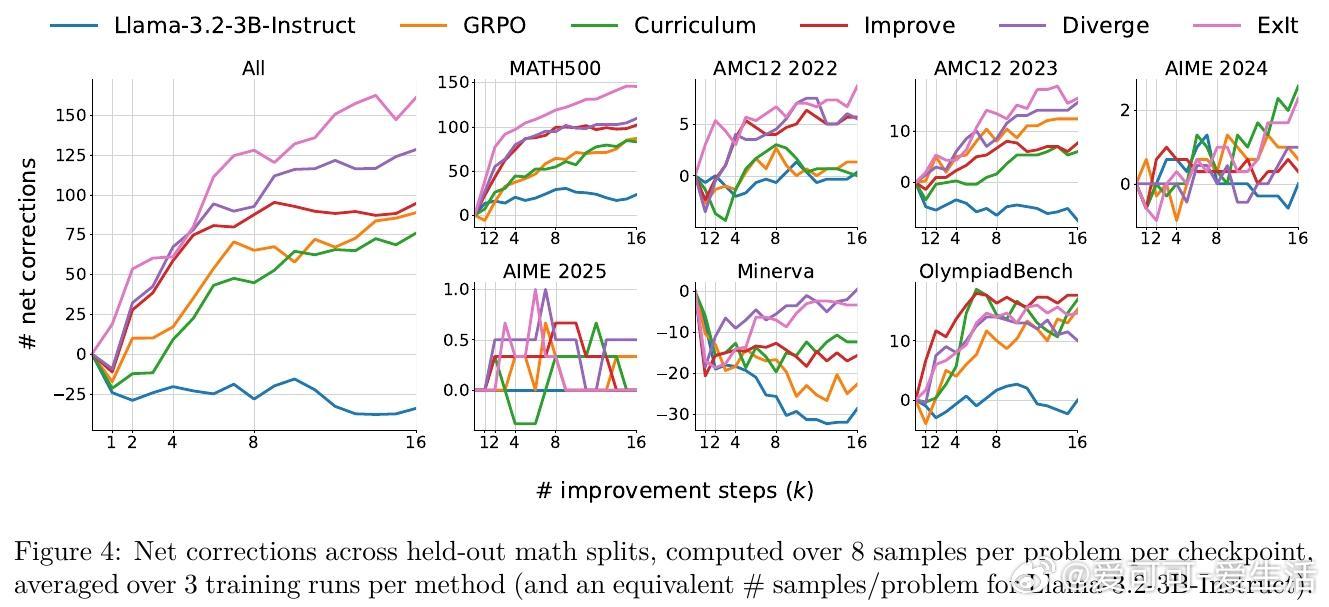
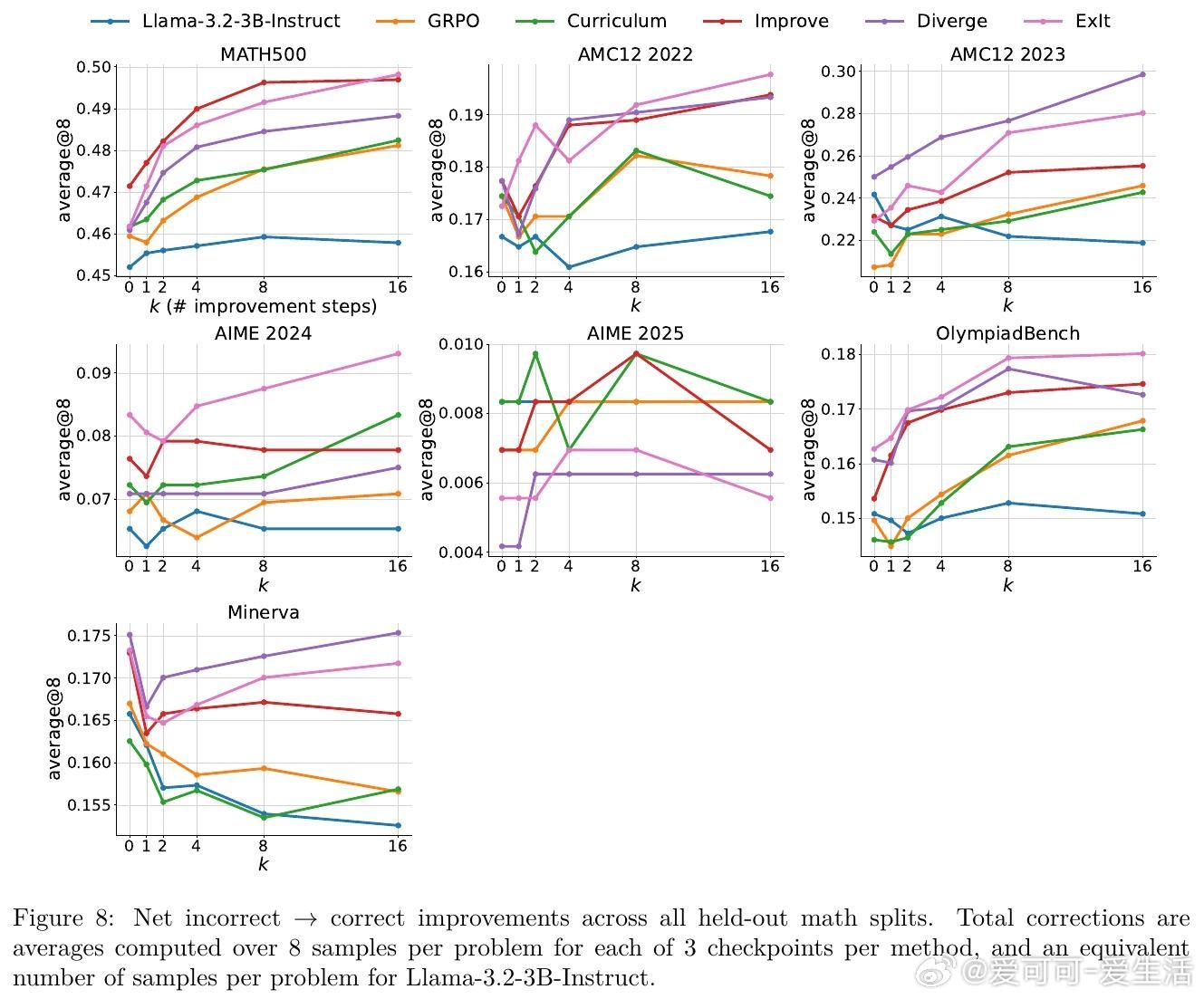
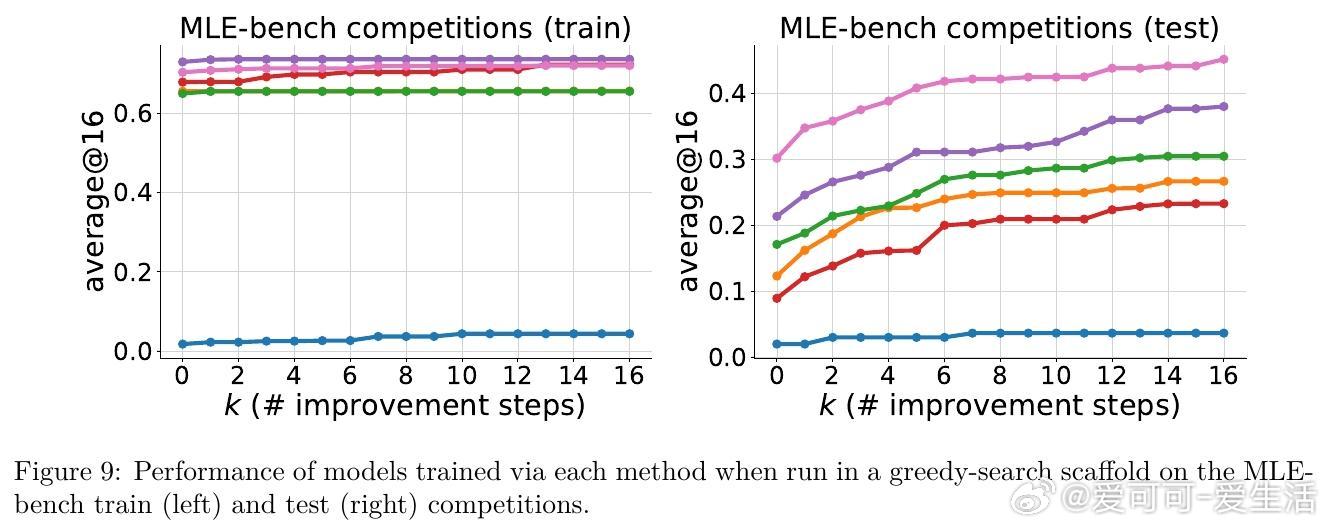
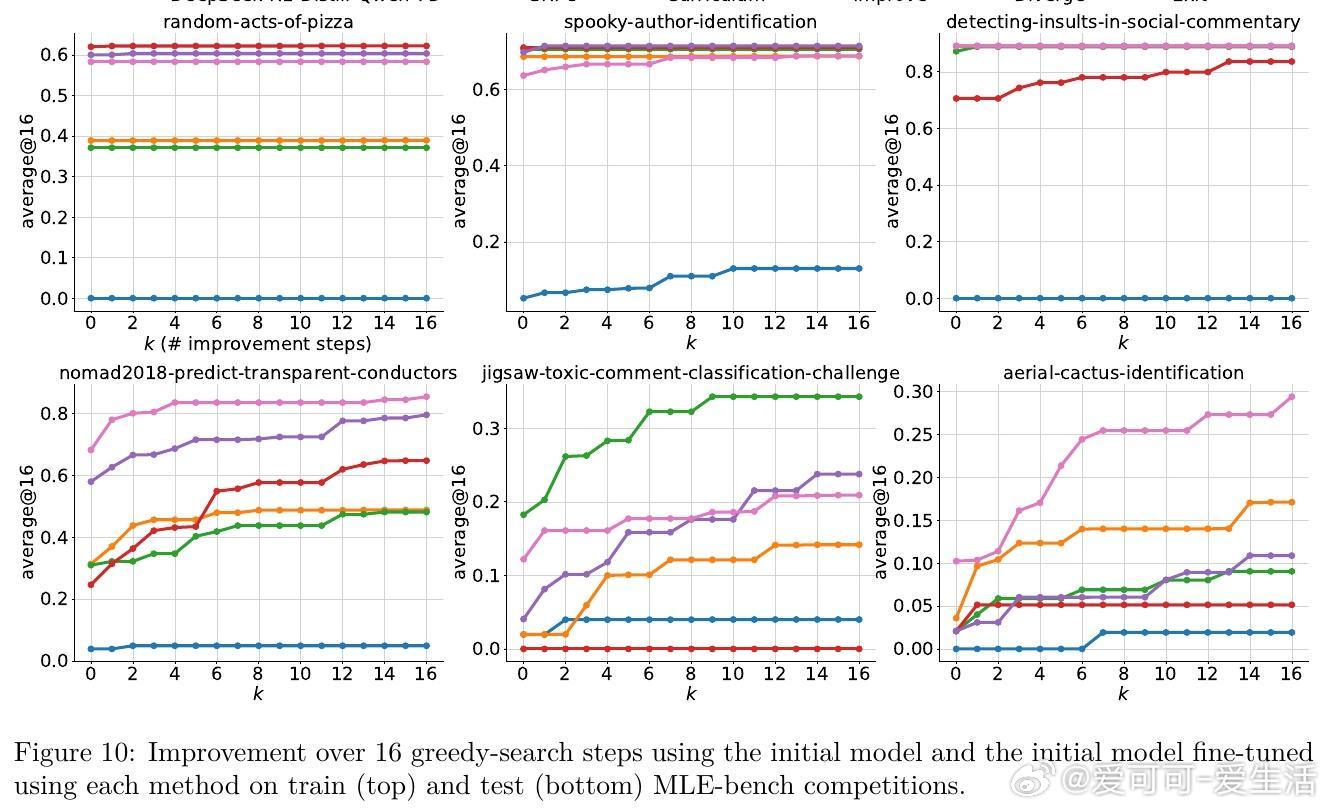
• 跨数学竞赛题、多轮工具调用及机器学习工程真实Kaggle任务验证,ExIt显著提升模型推理阶段的自我纠错和优化能力。
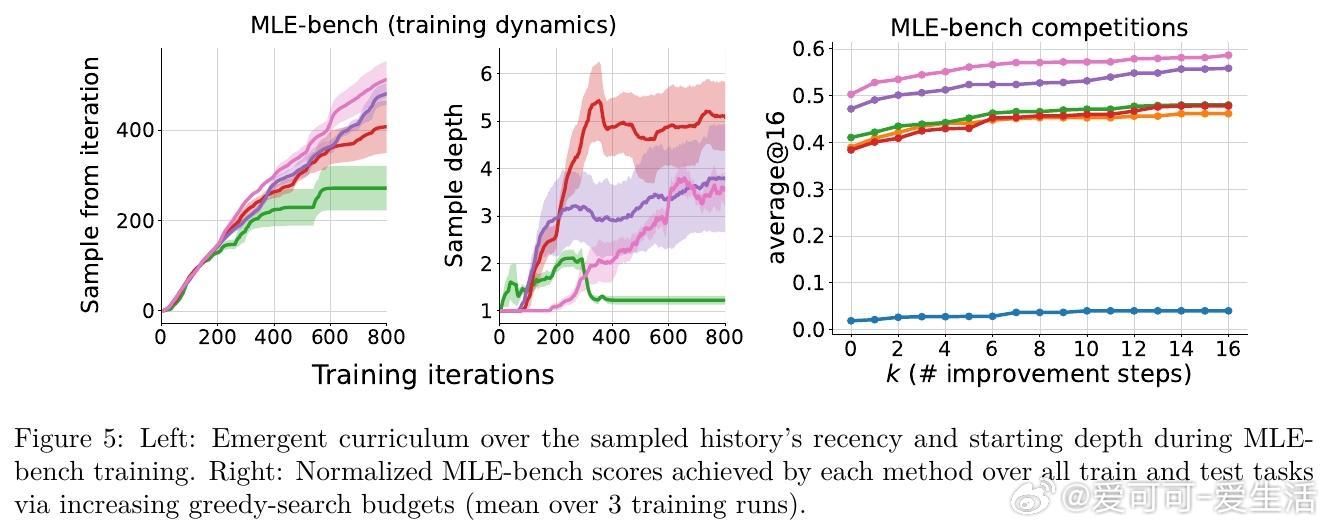
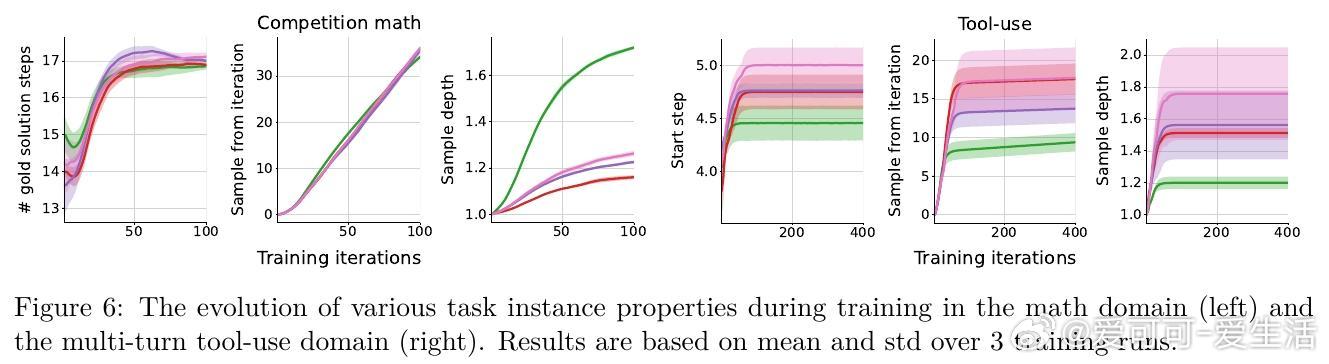
• 训练过程中自动生成难度递增的自适应课程,推动模型逐步攻克更复杂问题,无需外部任务排序指导。
• 结合Group-Relative Policy Optimization(GRPO),强化奖励归因,减少训练资源需求,提升稳定性与效率。
• 任务空间多样性增加,避免传统RL训练中因过度拟合导致的性能瓶颈,适合复杂多轮及搜索脚手架环境。
心得:
1. 任务空间自我扩展激发模型潜力,优先训练“最有提升余地”的样例比盲目多步训练更高效。
2. 单步迭代训练拆解复杂多步推理,突破传统训练深度限制,实现推理时更深层次的自我改进。
3. 多样性驱动的探索机制是防止模型陷入局部最优和单一策略的关键,提升泛化与创新能力。
详见🔗arxiv.org/abs/2509.04575
强化学习大语言模型自我提升自动课程推理优化任务空间探索