[CL]《Knowledge Collapse in LLMs: When Fluency Survives but Facts Fail under Recursive Synthetic Training》F Keisha, Z Wu, Z Wang, A Koshiyama... [Holistic AI & University College London] (2025)
知识坍缩:大语言模型在递归合成训练下流畅依旧却事实失准的三阶段退化
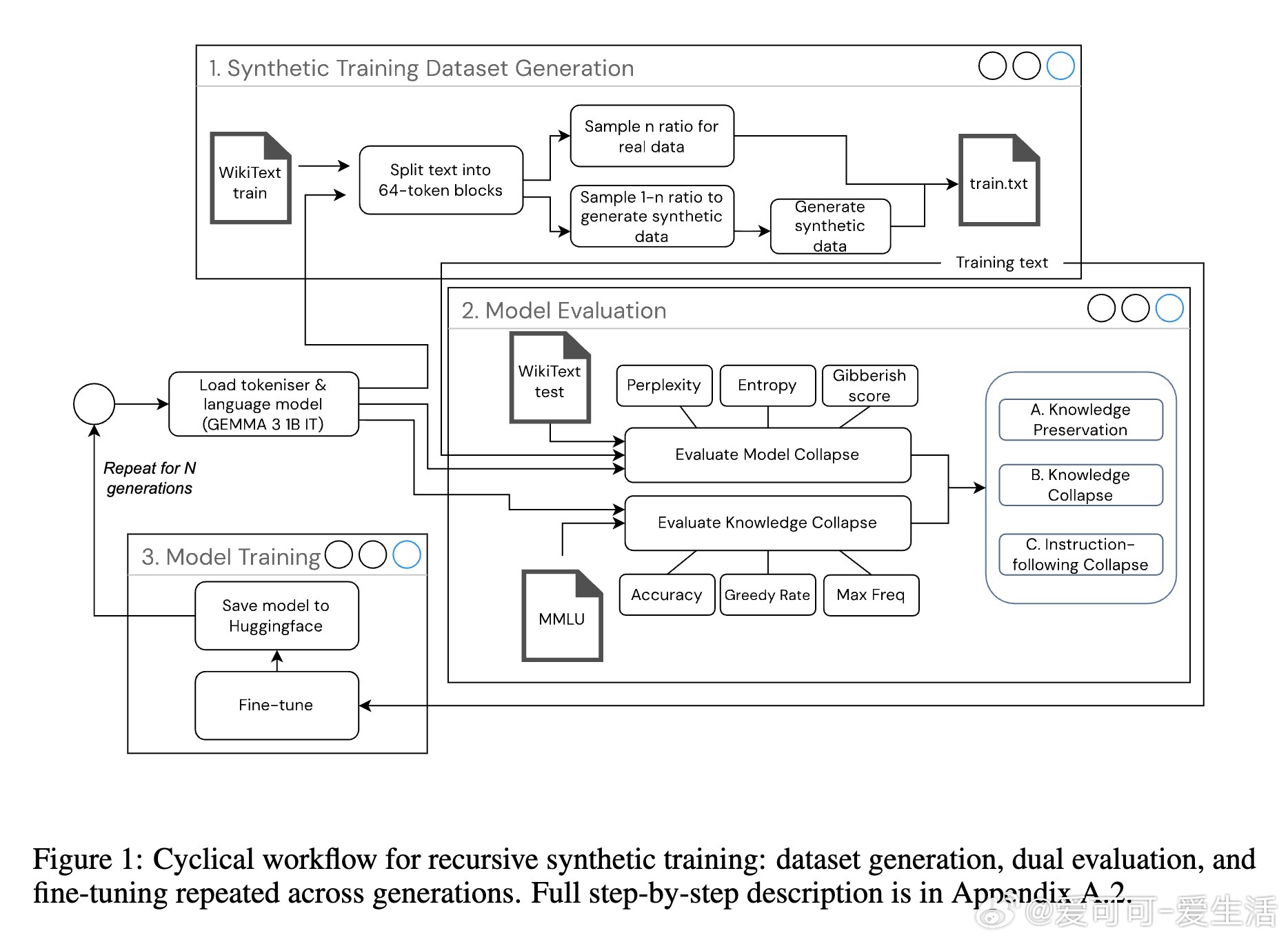
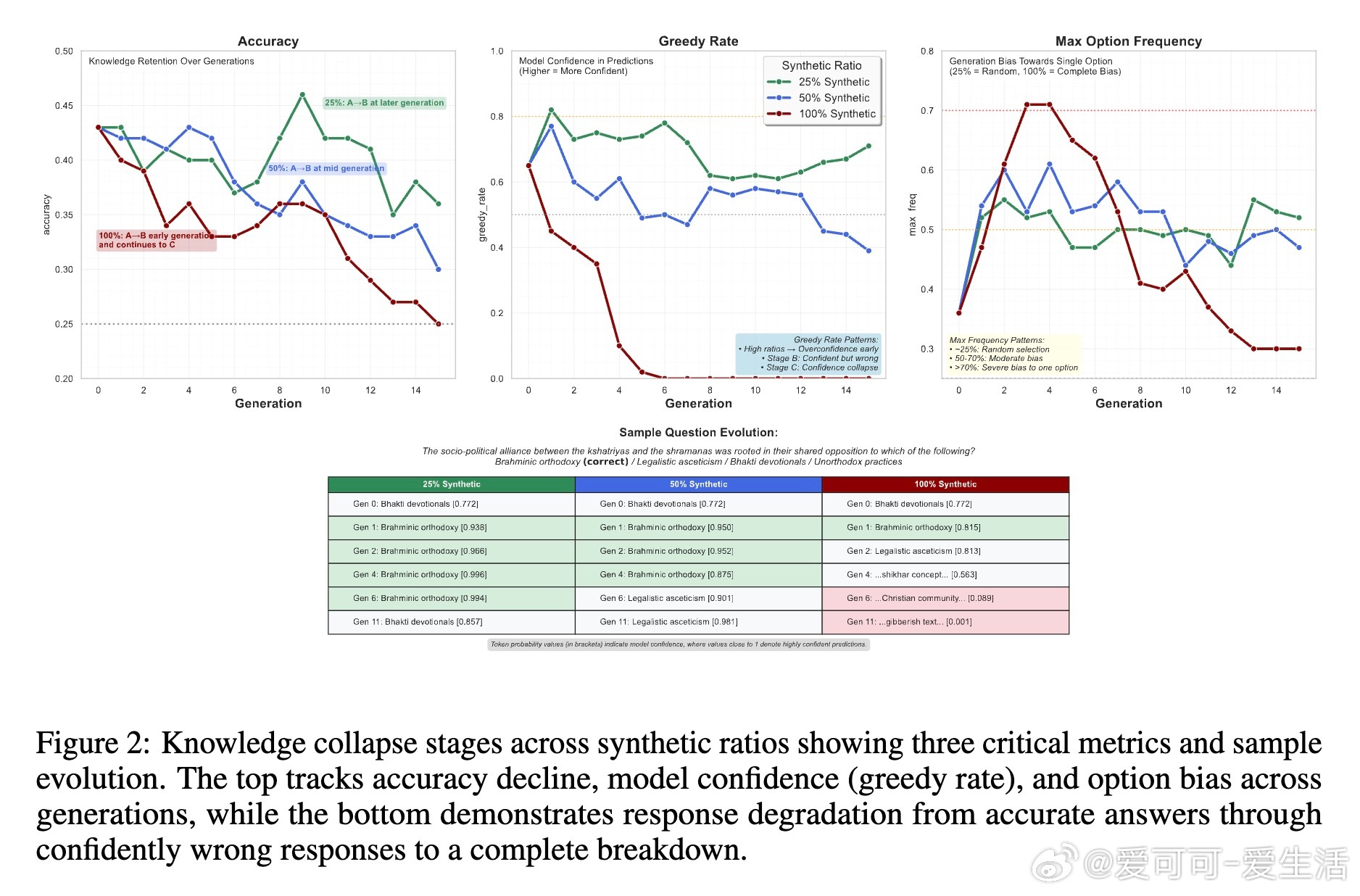
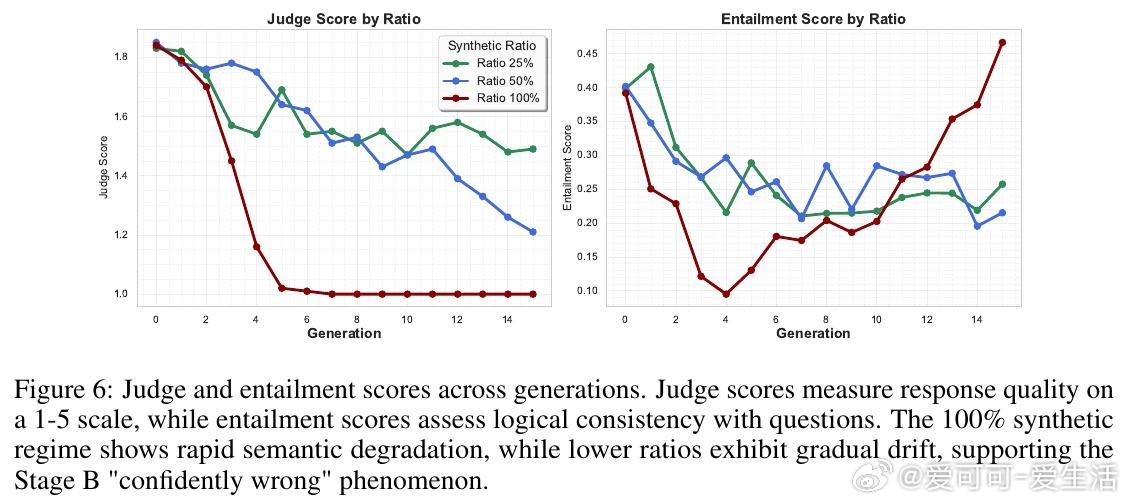
• 现象定义:知识坍缩分三阶段——A阶段(知识保留),B阶段(知识坍缩,即“自信错答”阶段,事实准确性下降但格式遵循仍强),C阶段(指令遵循坍缩,模型输出紊乱且准确率近随机)。
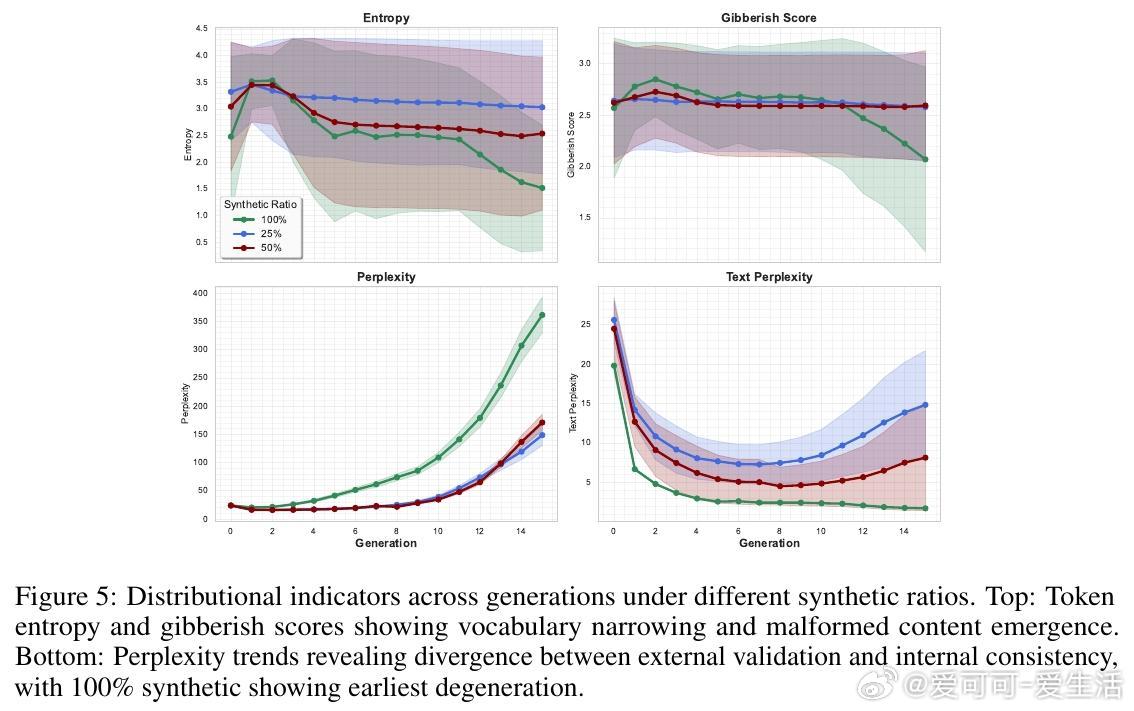
• 递归合成训练风险:随着训练中合成数据比例增高,知识崩塌加速,100%合成数据导致早期快速退化,现实数据混合(25%-50%合成)可延缓退化,展现不同坍缩轨迹。
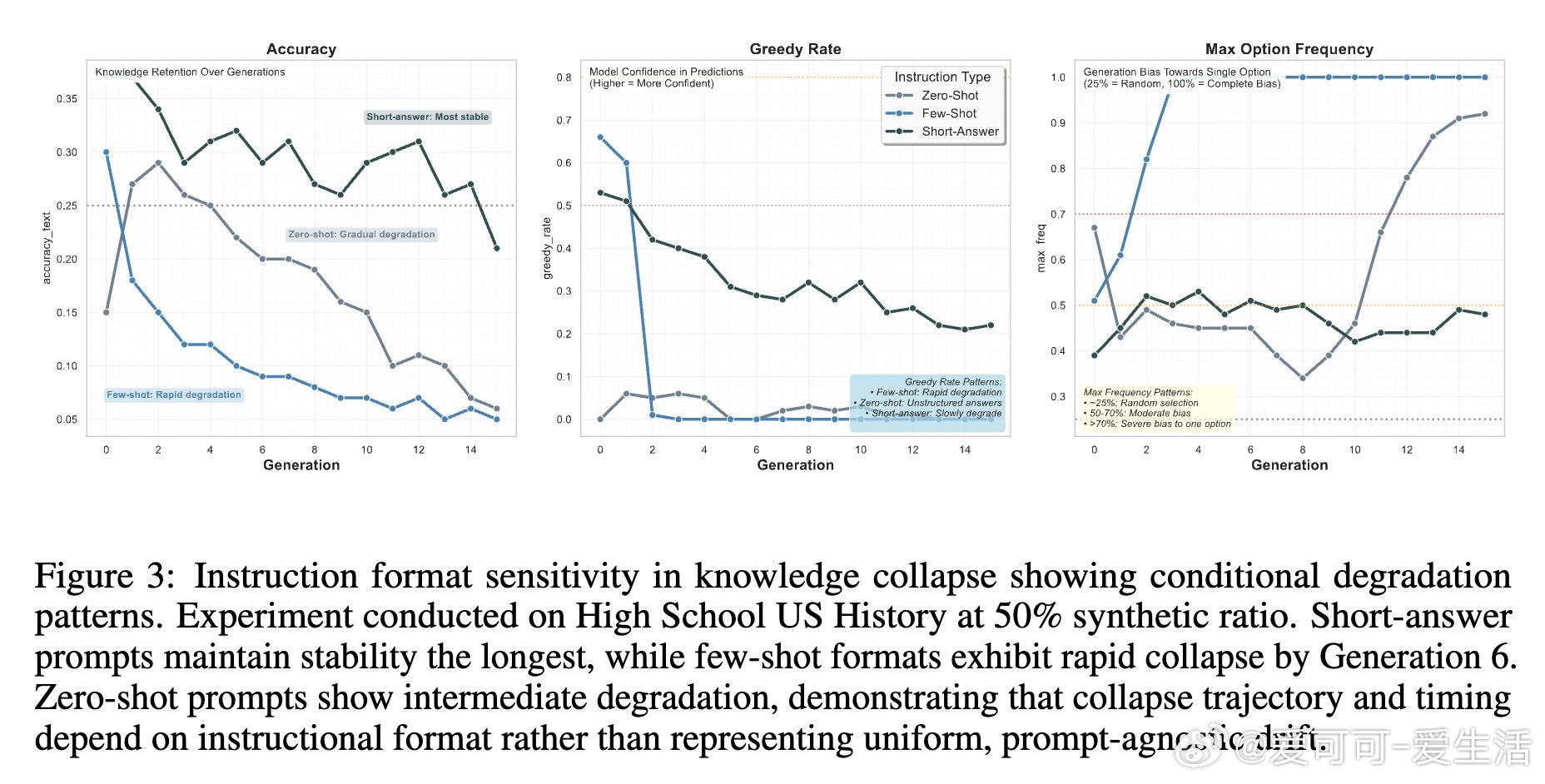
• 指令格式影响:复杂的few-shot示例加速坍缩,短答格式最稳定,指令依赖性导致崩溃非均匀发生,提示设计须重视格式简洁以延缓退化。
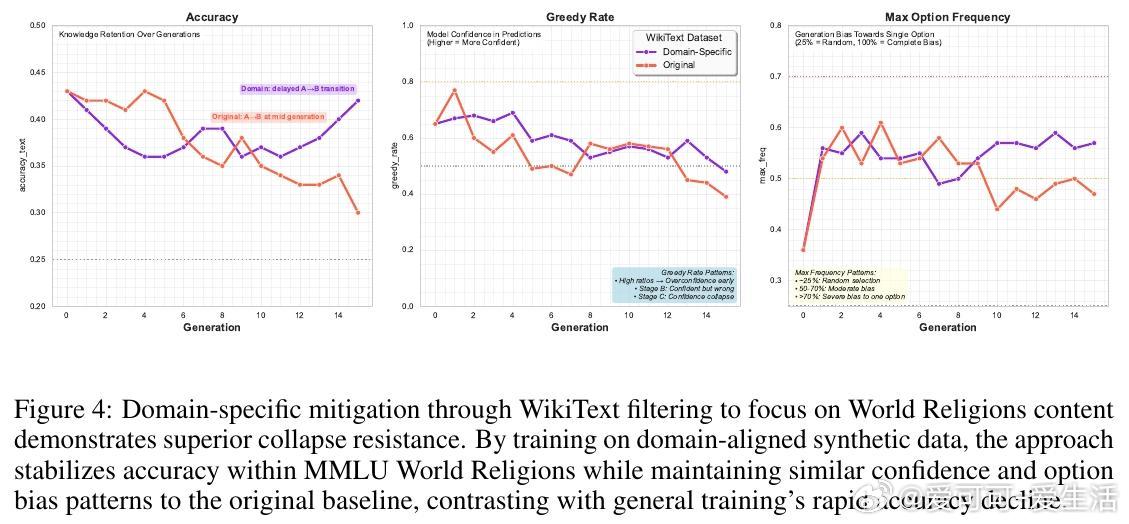
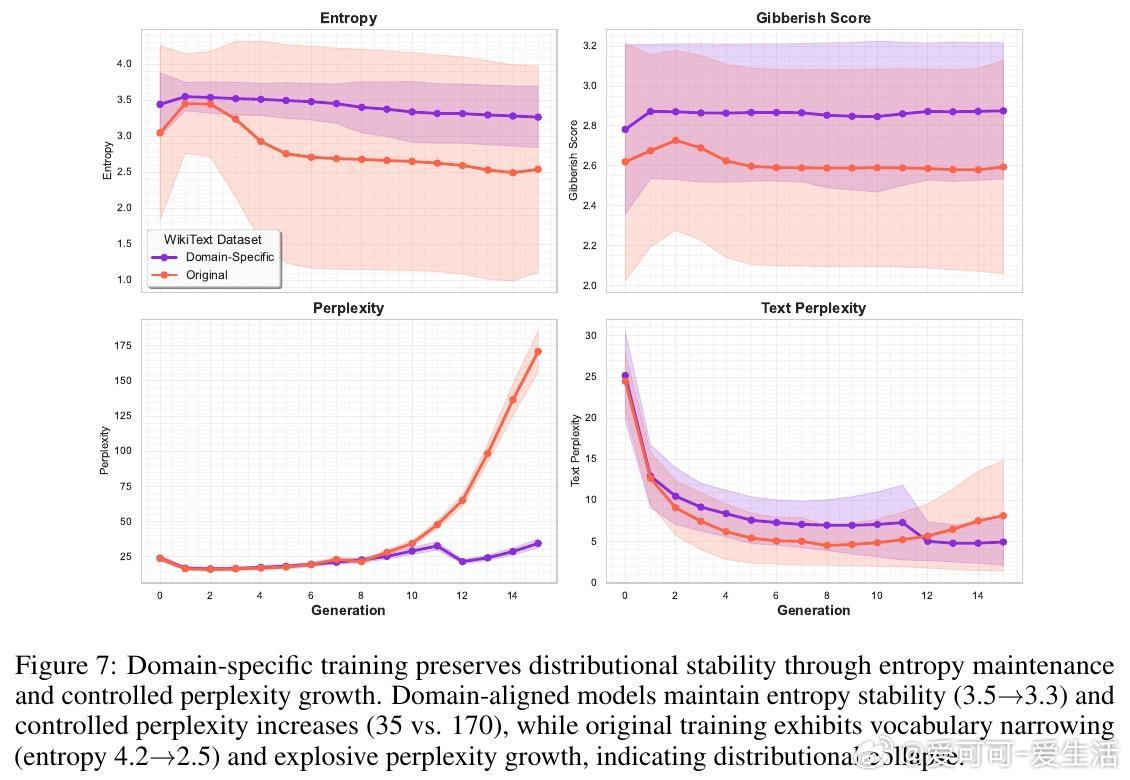
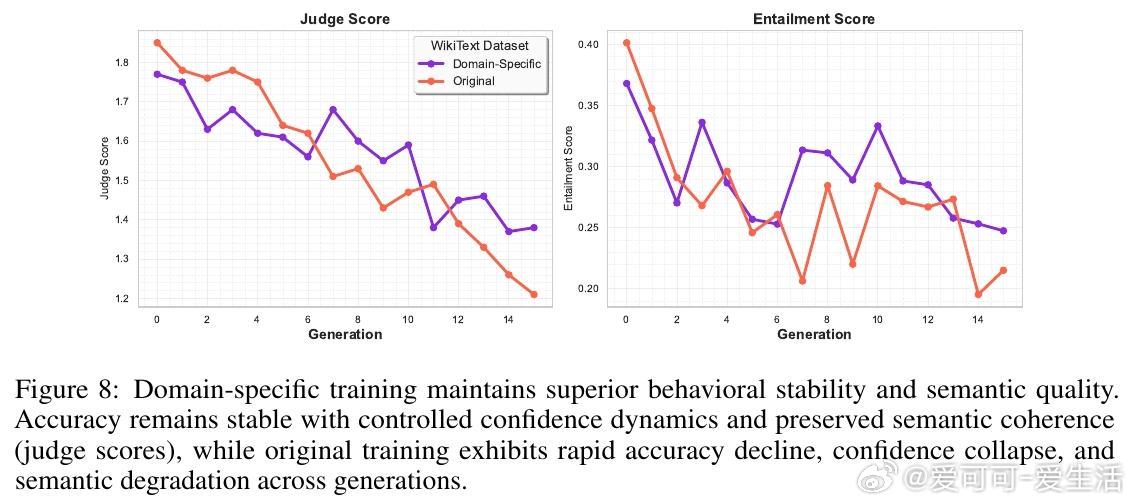
• 域专属训练缓解:针对特定领域(如世界宗教)构建合成训练语料,实现15倍知识坍缩延缓,保持词汇多样性和语义连贯,抑制模型早期过拟合合成数据模式。
• 评估框架:结合模型中心指标(困惑度、熵、无意义度)与任务中心指标(准确率、置信度、选项偏好),有效捕捉知识坍缩不同阶段,避免传统质量指标掩盖事实退化。
• 安全隐患:B阶段“自信错答”现象极具风险,模型在表面流畅的同时误导下游应用,特别在医疗等高准确率需求领域表现不佳(报错率高达40%)。
• 实验细节透明,使用GEMMA 3 1B IT模型、WikiText-2及MMLU多领域问答,提供可复现流程与开源框架,促进后续研究与实际部署安全。
心得:
1. 流畅与事实准确性可严重脱钩,单凭语言流利度指标无法保障模型输出的可靠性。
2. 递归训练中合成数据虽扩展规模,若无针对性设计,将加速知识退化,影响模型长期可用性。
3. 简化指令格式和域专属数据筛选是当前最有效的实用策略,强调训练数据分布对模型知识稳定性的决定作用。
详见🔗arxiv.org/abs/2509.04796
大语言模型知识坍缩递归训练合成数据模型安全指令设计域专属训练