[LG]《ParaThinker: Native Parallel Thinking as a New Paradigm to Scale LLM Test-time Compute》H Wen, Y Su, F Zhang, Y Liu... [Tsinghua University] (2025)
ParaThinker:突破LLM推理瓶颈的新范式,实现原生并行思考🚀
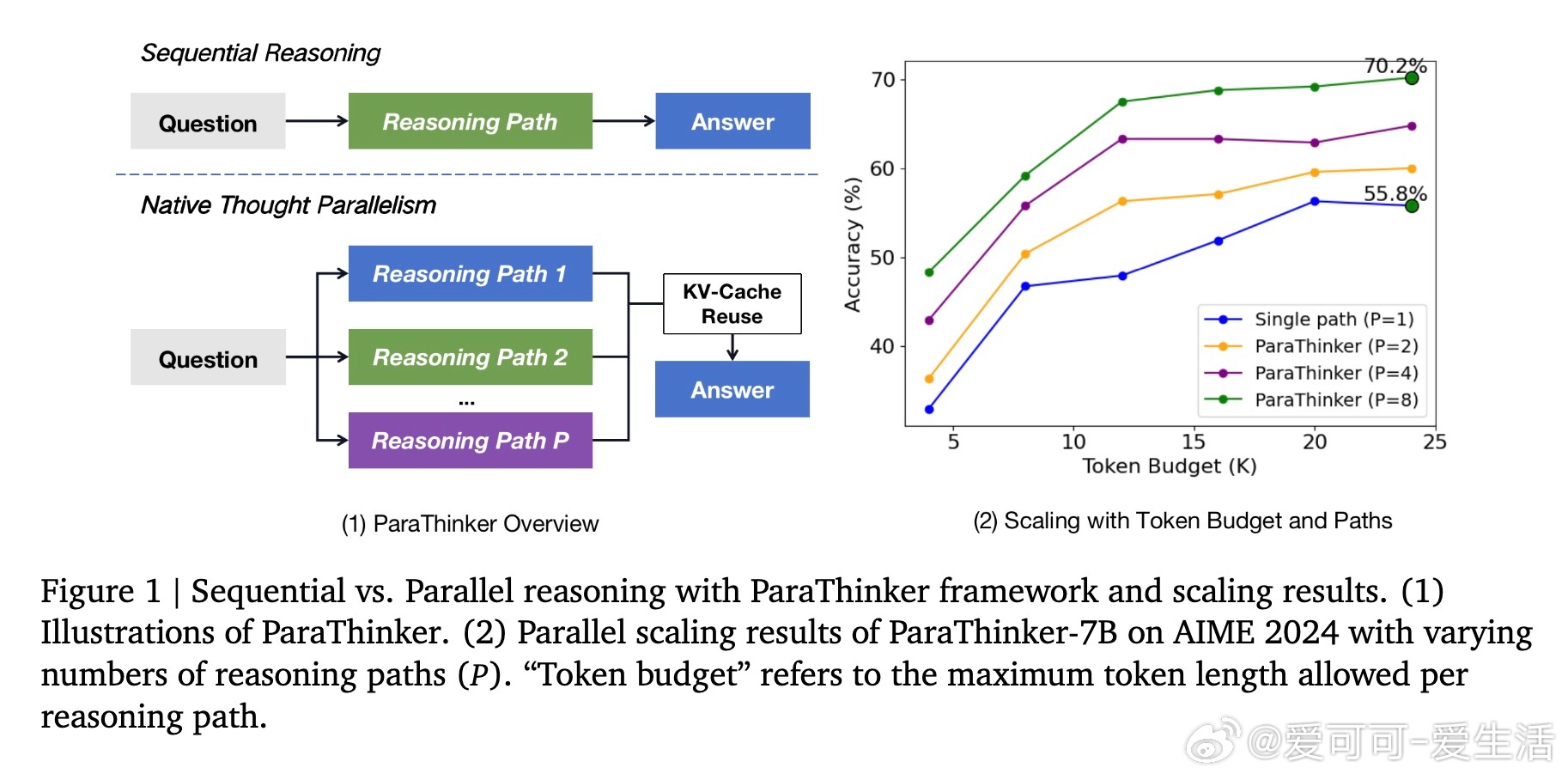
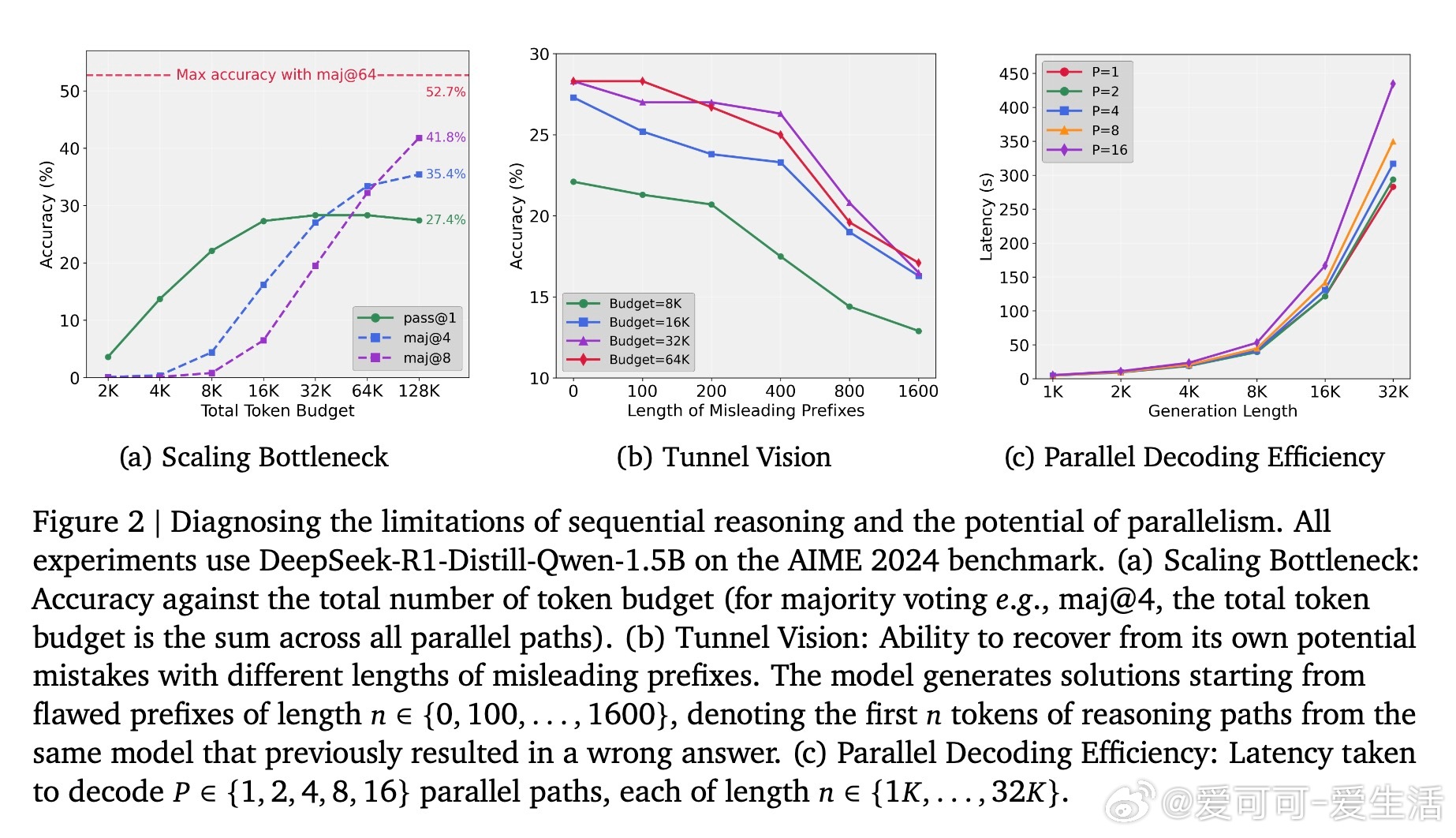
• 传统推理时时长计算通过延长单条思考序列提升推理能力,但存在“隧道视野”(Tunnel Vision)问题:模型早期思路若出错,后续难以纠正,导致性能瓶颈。
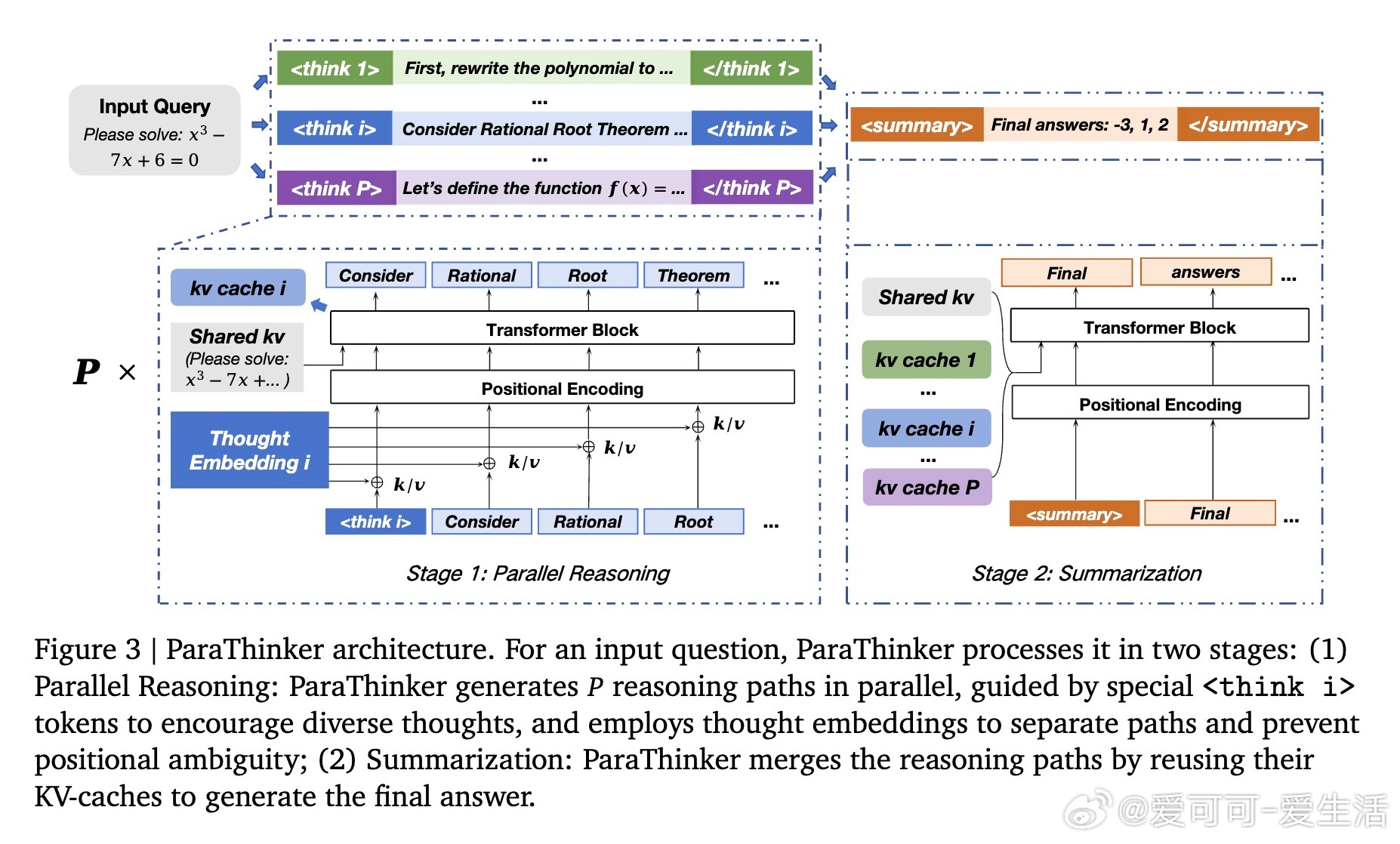
• ParaThinker引入“原生思考并行”策略,训练模型同时生成多条多样化推理路径,并通过专用控制token(等)引导不同思路,使用思路专属位置编码消除路径混淆,最终汇总多条路径得出更优答案。
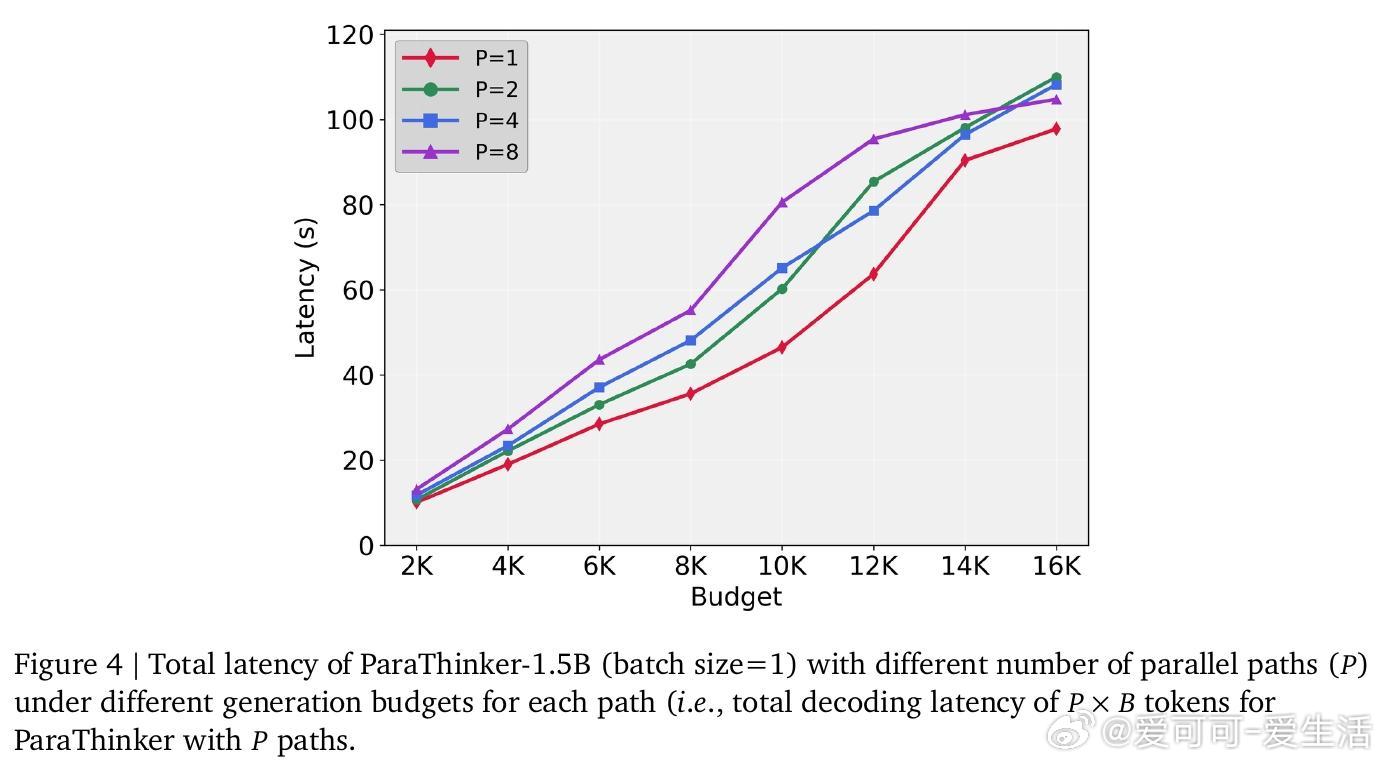
• 该方法不仅突破了单路径深度扩展的瓶颈,实现了宽度上的算力扩展,还显著提高推理准确率:1.5B与7B参数模型在挑战性数学任务上分别提升12.3%和7.5%,而延迟仅增加7.1%。
• 设计中两阶段推理架构—并行生成多条推理线索与汇总阶段复用KV缓存,极大提升计算效率,避免了传统多路径拼接带来的上下文重复加载开销。
• 训练采用大规模多路径数据集,随机采样控制token保证模型能推广到更多思考路径,具备良好扩展性。
• 实验验证多路径数目越多,准确率稳步提升,且首次完成策略(First-Finish)在终止时机上效果最佳,兼顾性能与效率。
• 相较多数投票等基于外部验证的并行方法,ParaThinker无需额外验证模块,适用更广泛开放式推理任务,未来可结合更复杂的聚合策略或强化学习进一步提升。
心得:
1. 推理质量瓶颈往往源于推理策略,而非模型能力本身,拓宽思考宽度比仅延长深度更有效。
2. 多路径并行解码不仅提升准确率,还能更高效利用硬件带宽,避免推理延迟线性增长。
3. 巧妙设计的控制token与思路专属位置编码是实现路径区分与高质量汇总的关键。
ParaThinker为LLM测试时算力扩展开辟了宽度维度,标志着推理范式的根本转变。
详情🔗arxiv.org/abs/2509.04475
代码🔗github.com/MobileLLM/ParaThinker
人工智能大语言模型并行推理机器学习自然语言处理