[LG]《AdaGrad Meets Muon: Adaptive Stepsizes for Orthogonal Updates》M Zhang, Y Liu, H Schaeffer [University of California, Los Angeles] (2025)
AdaGO:结合AdaGrad自适应步长与Muon正交更新的高效优化算法
• Muon优化器通过正交化动量更新矩阵权重,已在大规模语言模型训练中展现优异性能,但学习率调节尚无定论。
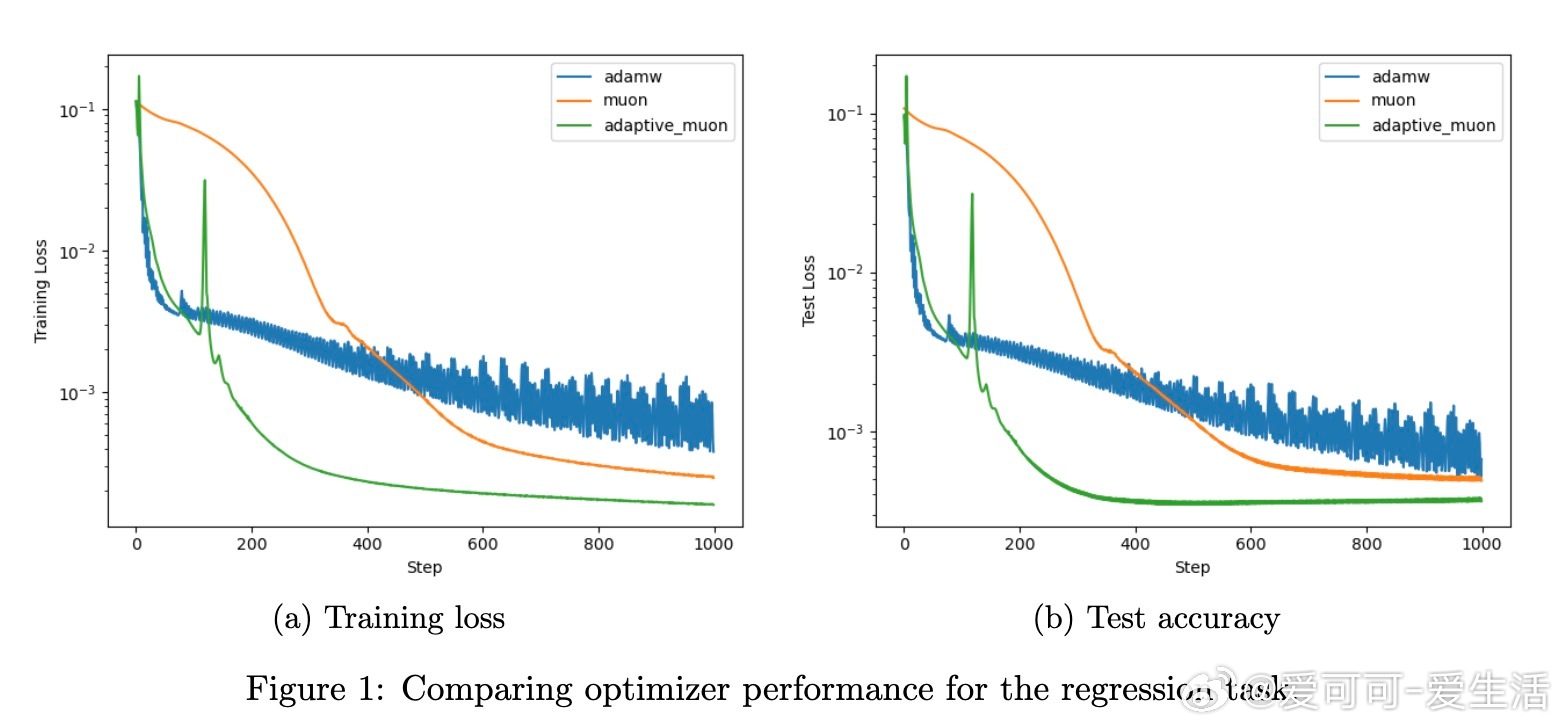
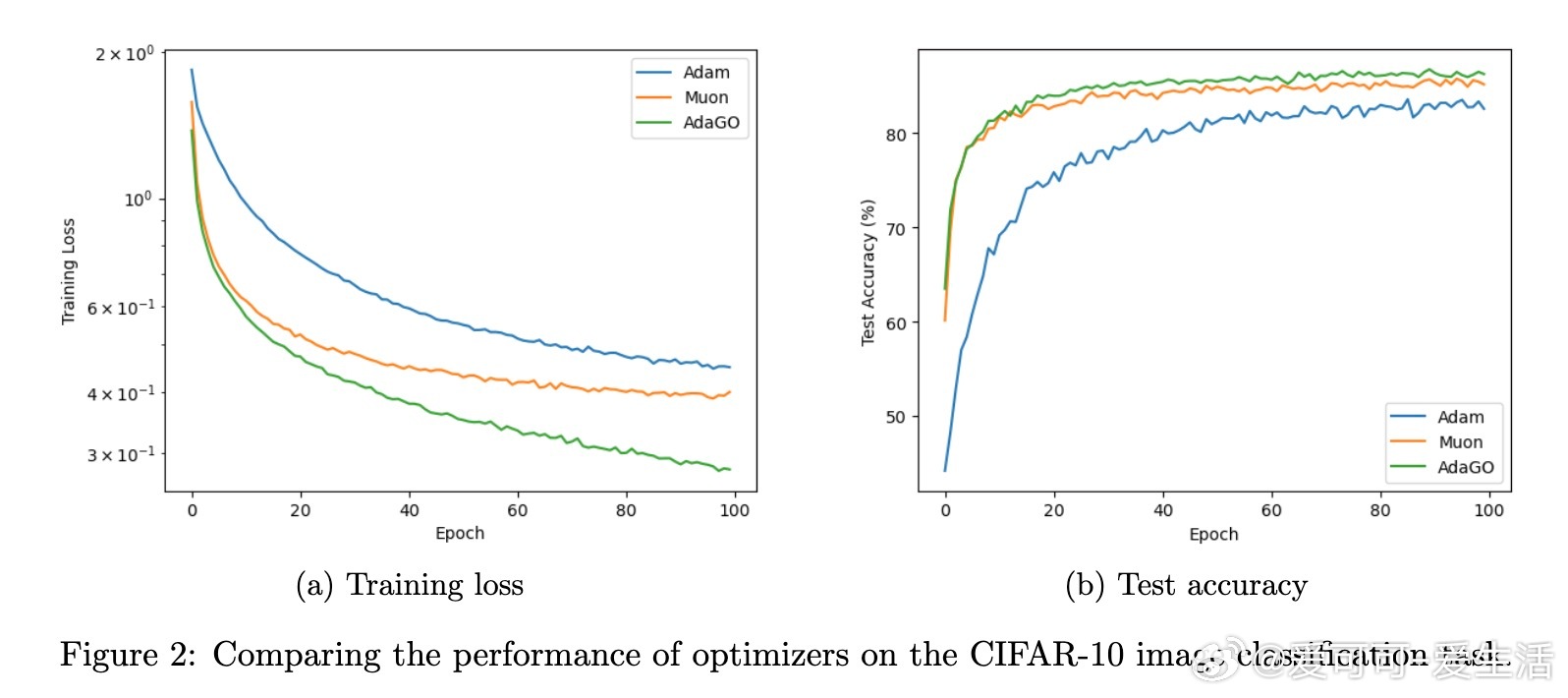
• AdaGO融合了基于梯度范数的AdaGrad步长与正交更新方向,既保持更新方向的正交性(等同于谱范数下降方向),又能根据累积梯度调整步长,适应复杂优化景观。
• 实现仅需在Muon基础上额外维护一个标量变量(累积梯度平方范数),计算和内存开销极低。
• 理论上,AdaGO在非凸优化中,满足标准光滑性与无偏有界方差噪声假设,达成最优收敛率:随机情形下收敛速率为O(T^{-1/4}),确定性情形达O(1/\sqrt{T})。
• 实验涵盖CIFAR-10图像分类与函数回归任务,结果显示AdaGO明显优于Muon和Adam,不仅训练更快且泛化性能更好。
心得:
1. 正交化更新改变了优化动力学,传统固定学习率难以兼顾初期快速收敛与后期稳定性,梯度范数驱动的自适应步长实现了动态平衡。
2. 保持更新方向正交性,避免了方向扭曲,保证了更新的谱范数最优属性,提高了优化路径效率。
3. 通过限制累积梯度范数避免噪声放大,AdaGO展现出对梯度噪声的自然适应能力,增强了算法鲁棒性。
更多细节请见🔗arxiv.org/abs/2509.02981
机器学习优化深度学习自适应优化正交更新Muon优化器AdaGrad