[LG]《Why Language Models Hallucinate》A T Kalai, O Nachum, S S. Vempala, E Zhang [OpenAI] (2025)
语言模型“幻觉”的根源与持续存在机制:
• 幻觉定义:语言模型在不确定时倾向“猜测”而非承认无知,产生貌似合理却错误的输出,这种现象被称为“幻觉”。
• 统计本质:幻觉非神秘现象,而是生成错误等同于二分类误判的自然结果。即语言模型在训练中难以将错误输出与真实事实区分开,尤其对罕见或仅出现一次的事实(如某人生日),错误率下限即与训练数据中的“单例率”相关。
• 训练机制:预训练阶段通过最大化语言数据分布似然,追求交叉熵最小化,天然导致模型生成错误或幻觉。即使训练数据无误,统计学习目标也难避免此类错误。
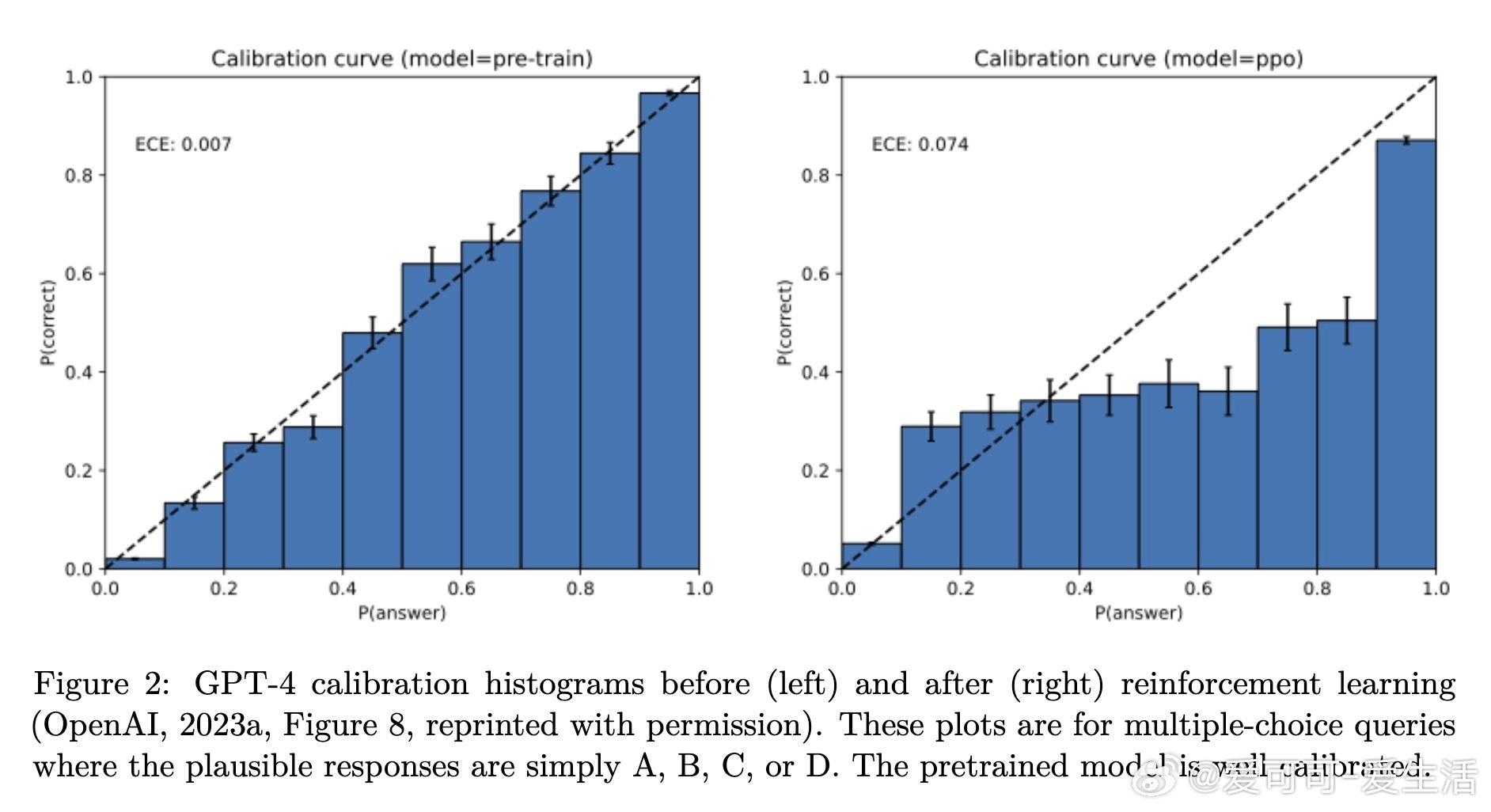
• 评估偏差:后训练阶段虽致力减少幻觉,但当前主流评测采用二元“对错”打分,严重惩罚模型表达“不知道”或“不确定”,鼓励模型“盲猜”,从而强化幻觉行为。
• 解决思路:应调整评测标准,引入显式的置信度阈值和允许模型适当回避回答(IDK),以激励模型表达真实不确定性,减少过度自信的错误输出。
• 统计框架:研究将生成错误归结为“Is-It-Valid”二分类问题,量化误分类率与生成错误率的关系,提供了理论下界;并结合计算复杂性、分布漂移、训练数据噪声等多因素,全面揭示幻觉形成原因。
• 现实启示:当前评测机制与语言模型训练目标存在根本不匹配,模型“考试思维”导致幻觉泛滥,只有构建与实际应用场景更契合的评测体系,才能根本遏制幻觉。
心得:
1. 语言模型的幻觉是训练目标与评估机制的产物,不是模型能力的简单缺陷,解决路径应从制度设计入手。
2. 二元对错评价体系对不确定性表达的惩罚,扭曲了模型行为,使得“装懂”成为最优策略,呼唤更细腻的置信度管理。
3. 理论与实践结合,明确幻觉与统计误分类的对应关系,为未来设计更可信、稳健的语言系统提供了坚实基础。
🔗 cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
语言模型人工智能机器学习模型评估AI安全