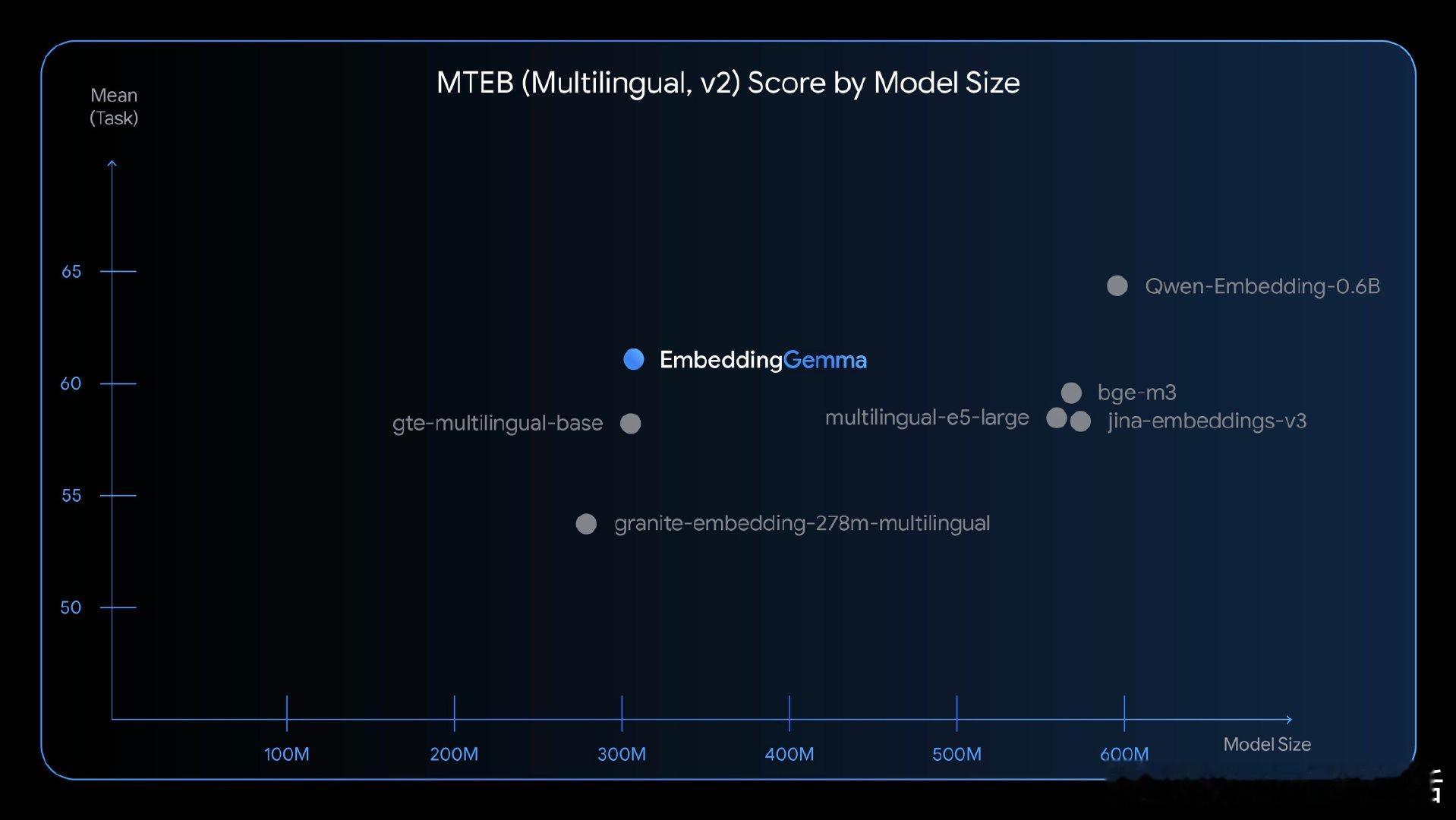
EmbeddingGemma:轻量级多语言嵌入模型的全新标杆
• 仅 3.08 亿参数,市面上 5 亿参数以下表现最优开源模型
• 支持 100+ 语言,覆盖全球主要语言体系,适配多语境应用场景🌏
• Matryoshka 结构提供灵活嵌入维度选择,768 到 128 维自由转换,兼顾精度与效率
• 兼容主流开源工具,方便集成到现有 AI 流水线与应用中🤗
• 运行内存低至 200MB,极大降低设备端部署门槛,实现真正移动端和边缘计算应用
• 社区支持和生态快速成长,已上线 Ollama、Baseten 等平台,助推落地加速
EmbeddingGemma的设计突破了“大模型=高资源消耗”的常规认知,展示了通过结构创新和多语言训练实现高效、实用嵌入模型的可能性。对于追求低延迟、离线及多语种支持的开发者与产品团队,这无疑是一款极具潜力的基础设施组件。
了解详情🔗developers.googleblog.com/en/introducing-embeddinggemma
模型直链🔗huggingface.co/google/embeddinggemma-300m
集成示例🔗baseten.co/library/embeddinggemma
嵌入模型 多语言AI 轻量级模型 边缘计算 开源AI