[LG]《Imitate Optimal Policy: Prevail and Induce Action Collapse in Policy Gradient》Z Zhou, Y Yang, Z Chen, F Bie... [University of Sydney & King Abdullah University of Science and Technology] (2025)
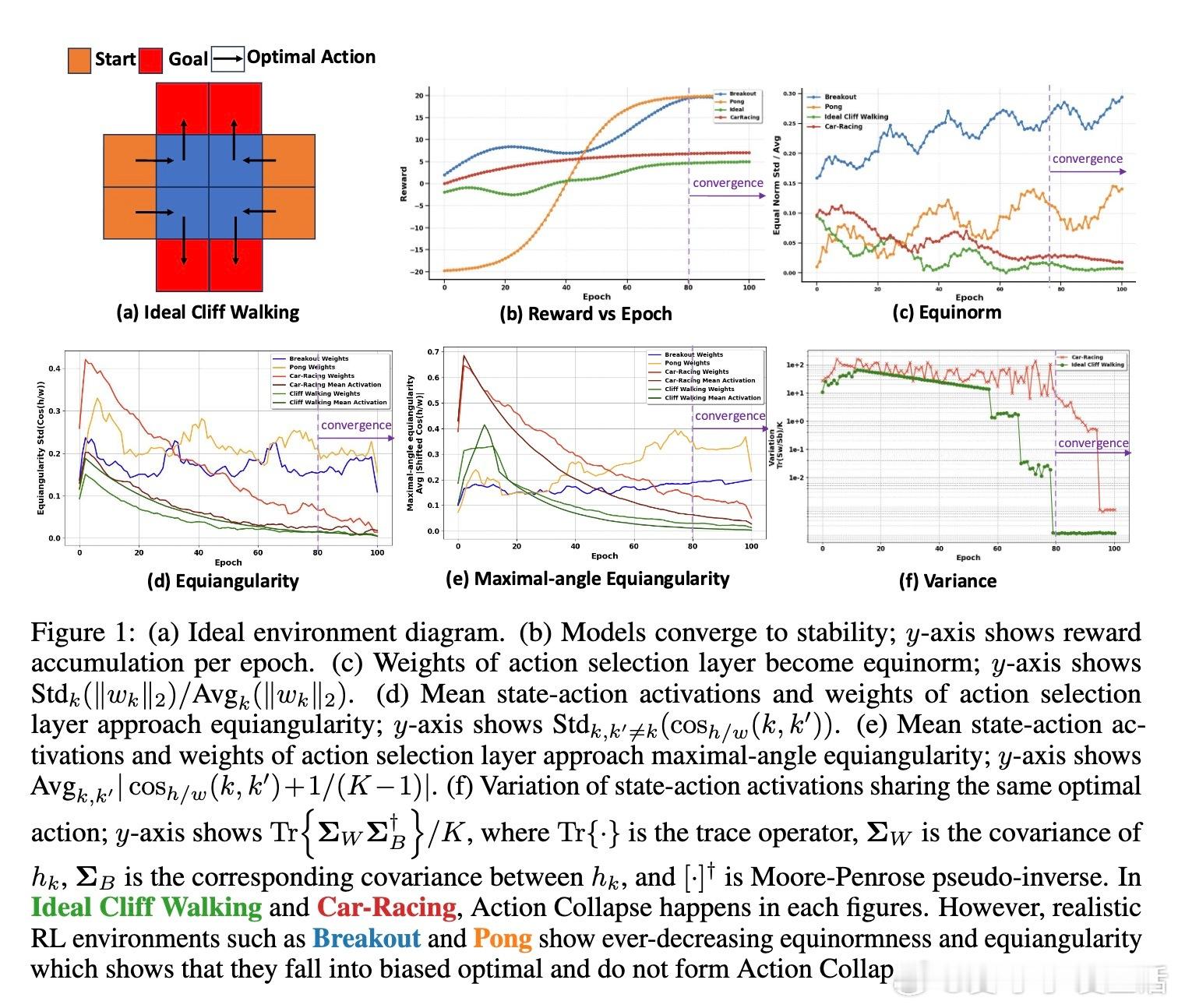
强化学习中的策略梯度(PG)方法通常依赖深度神经网络(DNN)学习状态-动作特征表示以计算动作选择概率。本文首次揭示了训练最优策略DNN时,隐藏层特征与动作选择层权重在理想条件下呈现出一种特殊几何结构——“动作塌缩”(Action Collapse),其核心表现为:
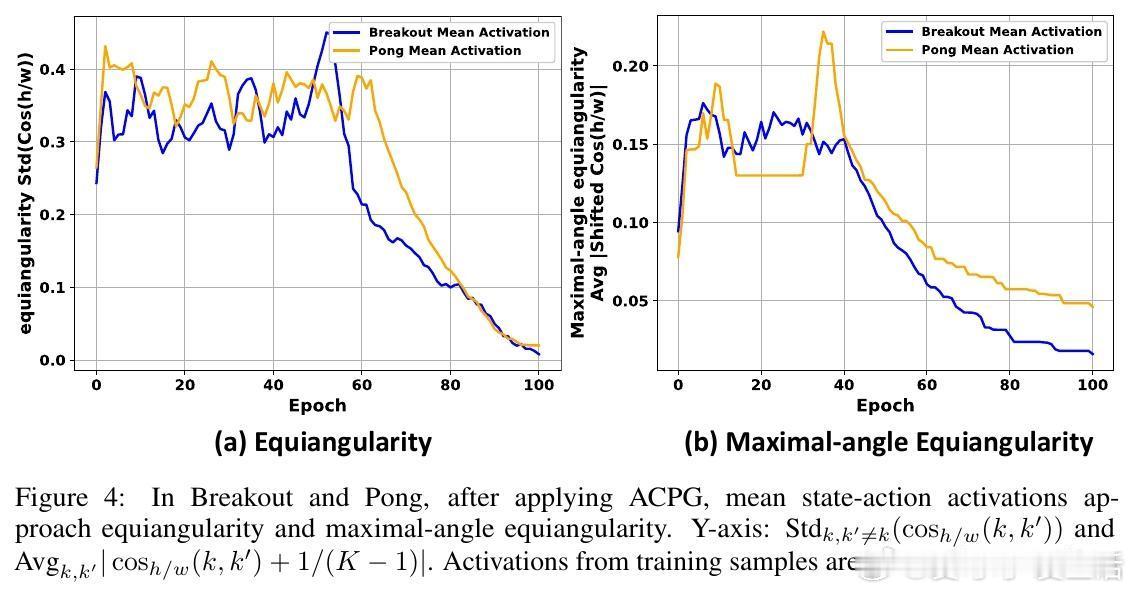
• 同一最优动作对应的状态-动作激活特征(最后一层特征)趋向该动作的均值激活,且该类激活的内部变异性收敛至零;
• 动作选择层权重与均值激活共同收敛形成一个简单等角紧框架(simplex Equiangular Tight Frame, ETF),最大化了动作间的角度分离度;
• 该结构与经典“神经塌缩”(Neural Collapse)现象相呼应,揭示了最优策略网络的潜在几何对称性。
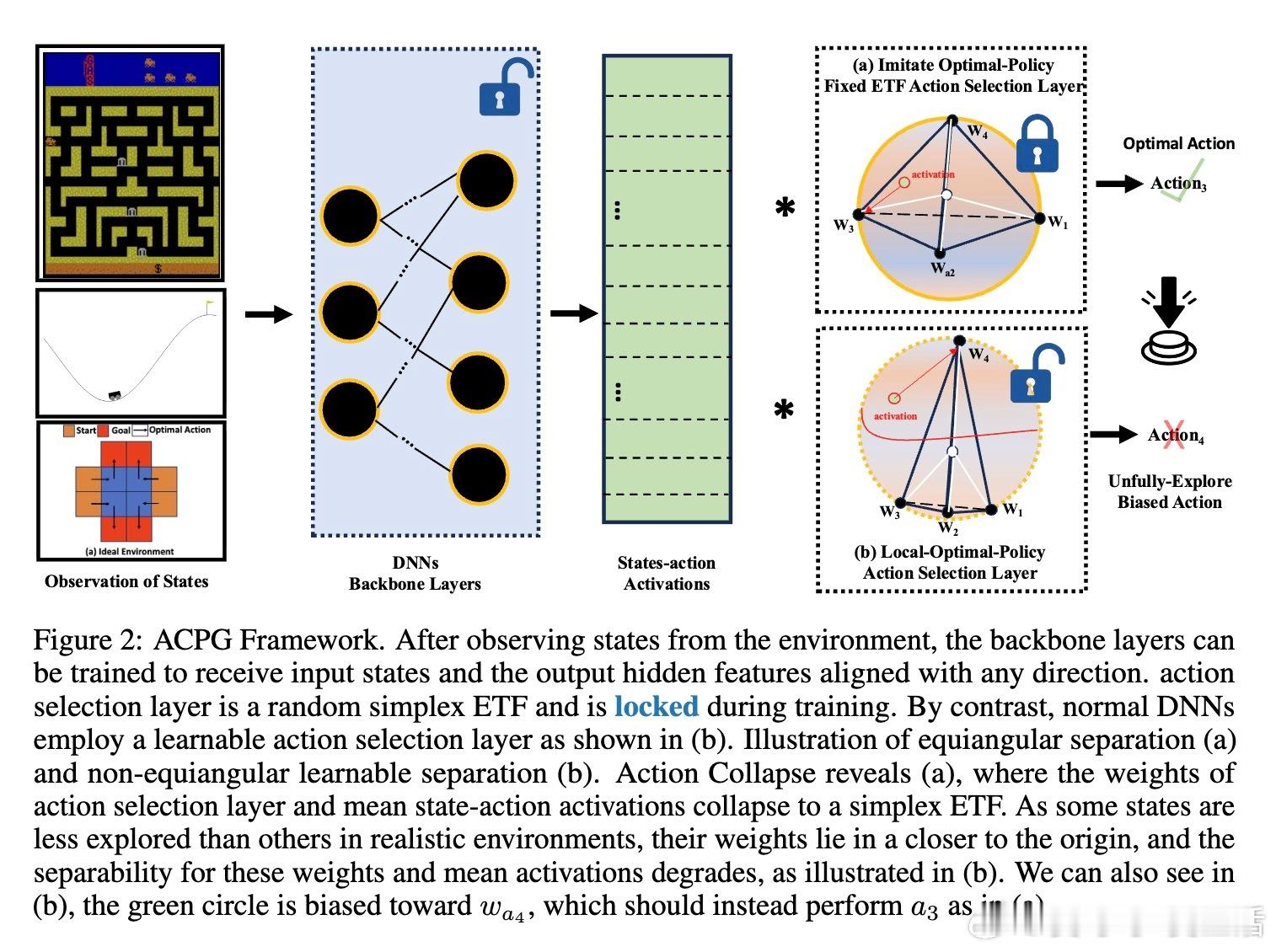
针对现实强化学习环境中因状态-动作样本不均衡和不足探索导致动作塌缩难以自然形成的问题,作者提出了固定动作选择层为合成ETF的“动作塌缩策略梯度”(Action Collapse Policy Gradient, ACPG)方法。该方法通过:
• 预设动作选择层权重为简单ETF,不参与训练,仅优化状态-动作激活;
• 理论证明无论样本是否均衡,ACPG均可诱导激活向ETF结构收敛,实现动作塌缩;
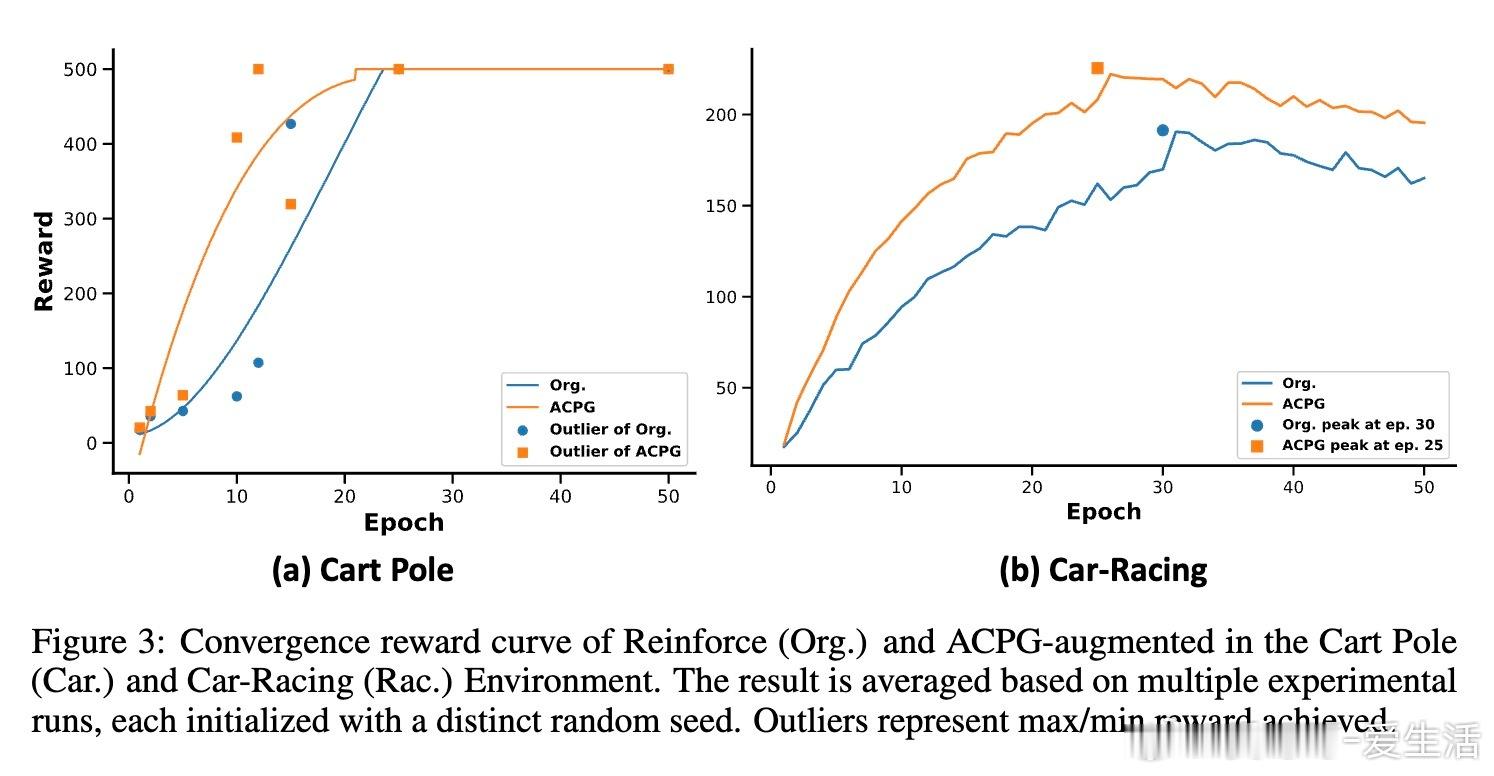
• 在OpenAI Gym多个环境(包括CartPole、Car-Racing、Atari等)和多种PG算法(REINFORCE、TRPO、PPO、A3C)中,ACPG均显著提升了训练速度、稳定性和最终收益,部分环境提升幅度超过50%以上。
心得:
1. 最优策略的几何结构并非随机,而是高度对称的ETF形状,这启发我们从几何视角设计和理解策略网络。
2. 固定动作选择层权重简化了训练过程,避免了传统可训练层陷入局部最优的风险,促进更快收敛。
3. 适度探索对于诱导动作塌缩至关重要,体现探索与利用平衡在几何结构形成中的关键作用。
详情见👉 arxiv.org/abs/2509.02737
强化学习策略梯度神经塌缩EquiangularTightFrame深度学习人工智能