[LG]《Cut Costs, Not Accuracy: LLM-Powered Data Processing with Guarantees》S Zeighami, S Shankar, A Parameswaran [UC Berkeley] (2025)
降低成本而不牺牲准确率:利用 BARGAIN 框架实现具备理论保证的大型语言模型(LLM)驱动数据处理
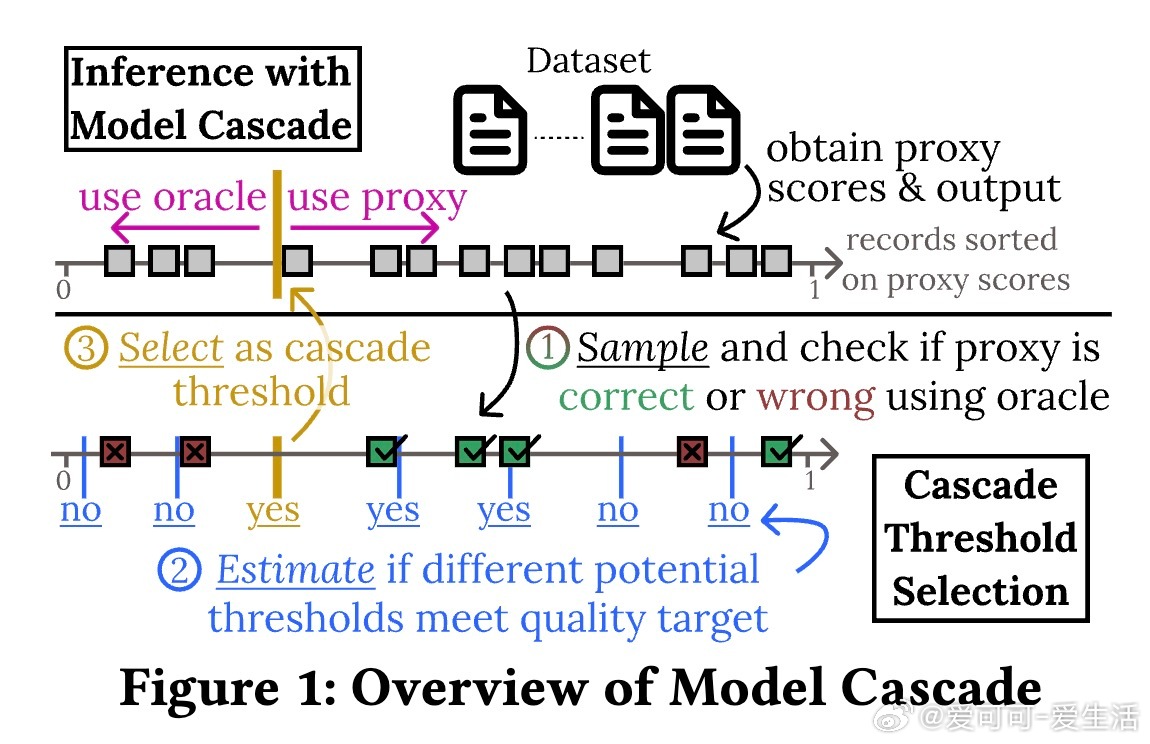
• 面对高昂的顶级 LLM(如 GPT-4o、Claude Sonnet)调用成本,BARGAIN 通过模型级联策略智能选择使用低成本代理模型(如 GPT-4o-mini、Claude Haiku)处理部分数据,确保整体输出质量不低于用户设定的准确率、精度或召回率目标。
• 创新自适应采样方法,结合数据分布和任务特性,高效采集关键样本,避免无效采样浪费资源。
• 基于最新统计推断工具(Waudby-Smith & Ramdas, 2024)设计严格的假设检验估计函数,实现对质量指标的准确估计,显著优于传统 Hoeffding 或 Chernoff 界限。
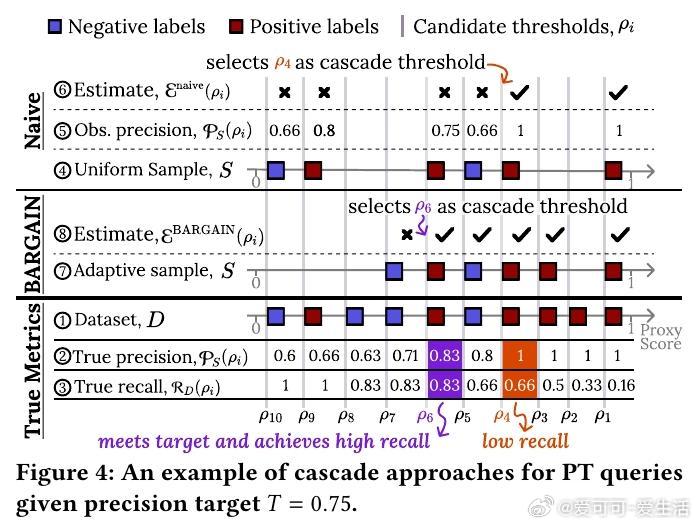
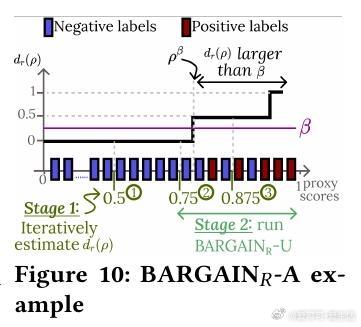
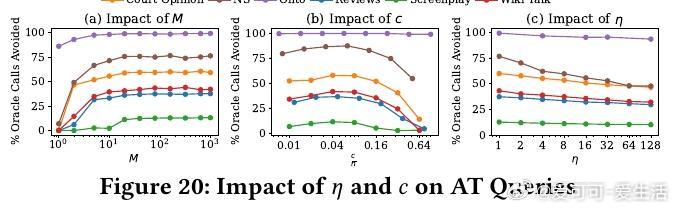
• 针对三类查询:准确率目标(AT Queries)、精度目标(PT Queries)、召回目标(RT Queries),分别设计并验证对应算法变体,支持多类别分类及不均衡数据场景。
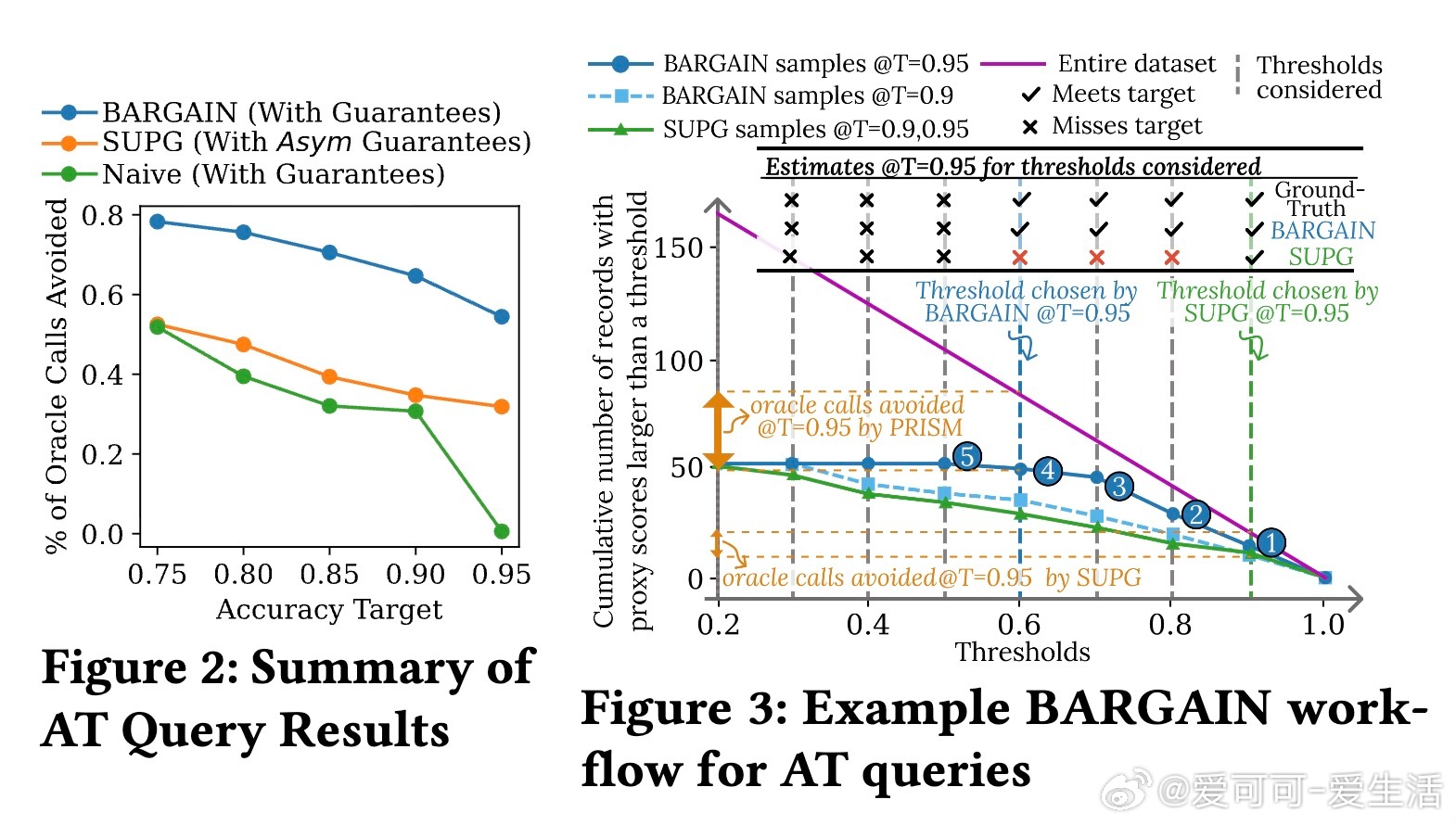
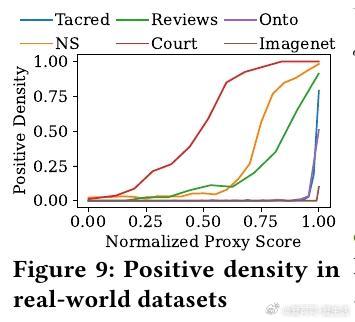
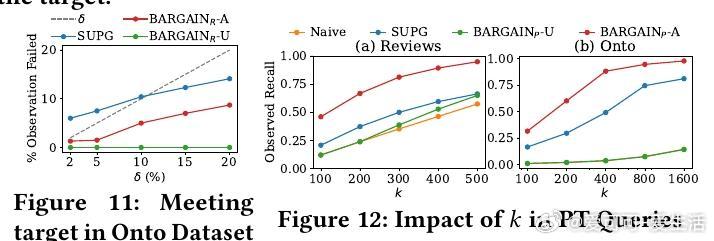
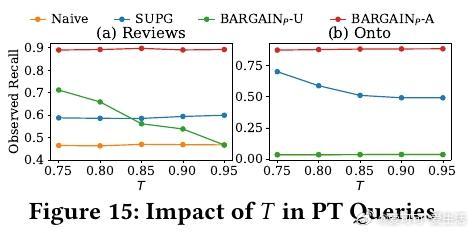
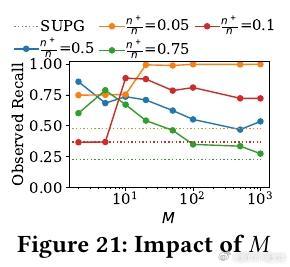
• 实验覆盖八个真实数据集,BARGAIN 在减少顶级 LLM调用次数方面较当前最优方法 SUPG 提升最高达86%,召回率和精度分别提升118%和19%,同时保证理论上的严格质量约束。
• 设计合理的候选阈值集参数设置,平衡采样效率和结果精度,实现实际应用中的稳健表现。
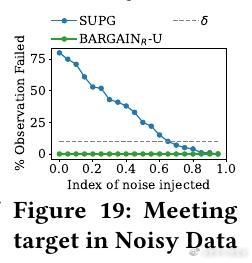
• 通过对抗性实验验证 BARGAIN 在模型未校准或数据分布极端时的鲁棒性,显著优于 SUPG,避免在关键任务中频繁失效。
• 支持多代理模型场景,能与现有代理路由策略结合,灵活适配复杂实际系统需求。
心得:
1. 质量保证不是“样本量越大越好”,关键在于采样策略和估计方法的合理设计,BARGAIN通过自适应采样与方差敏感检验,极大提升了小样本下的估计准确度。
2. 代理模型置信度(proxy score)的合理利用是成本控制的核心,BARGAIN创新地结合了任务特性和数据正负样本分布,避免了传统方法忽视这些信息导致的低效采样。
3. 理论保证与实际效用并非对立,BARGAIN以严谨的统计理论为基础,兼顾实用性和高效性,实验证明其在真实复杂数据上均表现卓越,值得在LLM驱动系统中广泛推广。
了解详情🔗arxiv.org/abs/2509.02896
人工智能大型语言模型数据处理模型级联统计推断成本优化机器学习