[LG]《Beyond Correctness: Harmonizing Process and Outcome Rewards through RL Training》C Ye, Z Yu, Z Zhang, H Chen... [Amazon] (2025)
强化学习奖励的细粒度与准确性难以兼得,如何协调过程奖励与结果奖励成为数学推理等任务的核心挑战。
• 传统Outcome Reward Models (ORMs)仅关注最终正确性,无法区分“正确答案中的错误推理”与“错误答案中的合理推理”,导致训练信号噪声大且误导性强。
• Process Reward Models (PRMs)提供逐步细粒度反馈,但易受数据偏差影响,常出现误判和奖励作弊(reward hacking)。
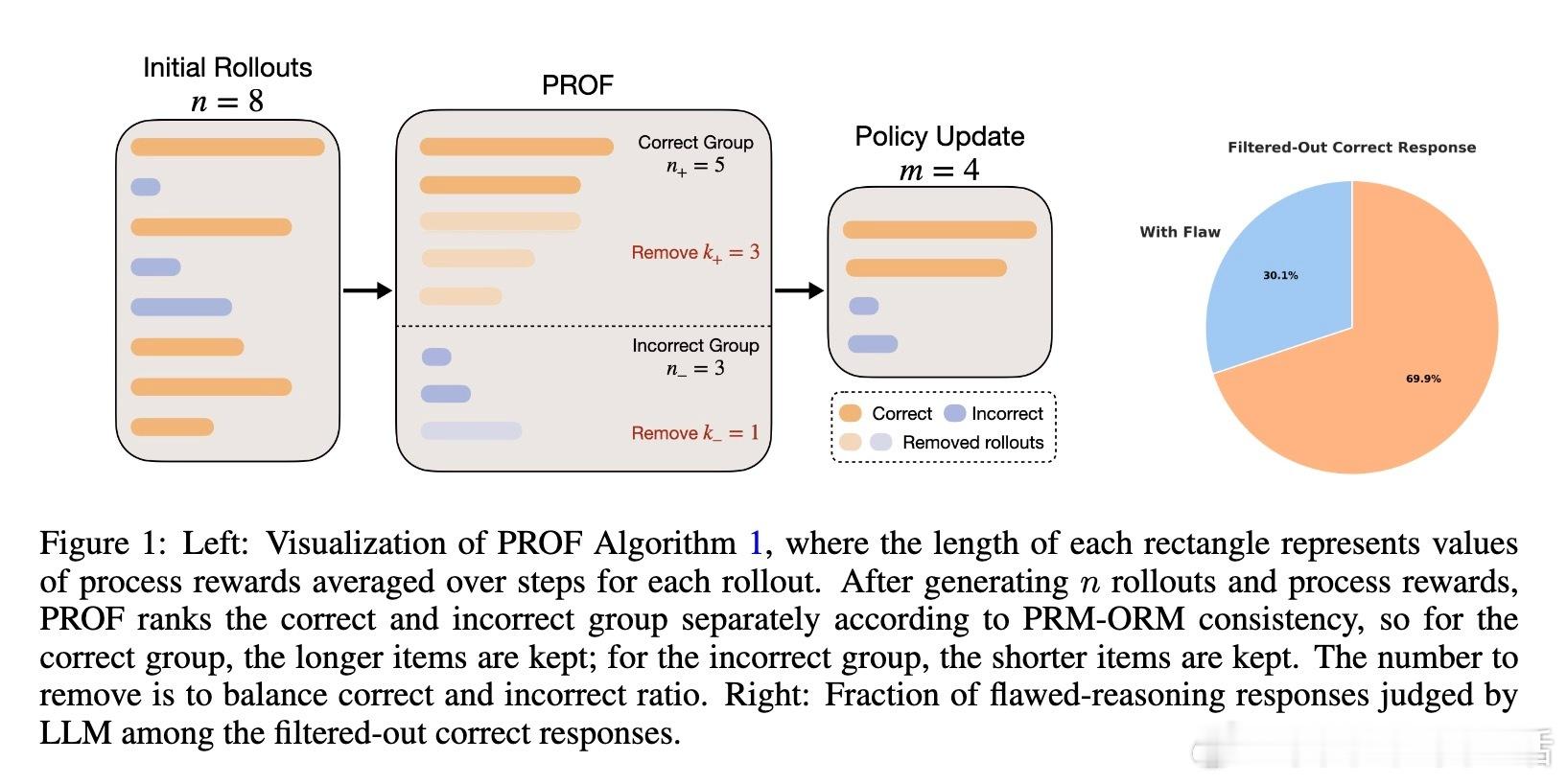
• PROF(Process cOnsistency Filter)框架通过一致性过滤机制,分别对正确与错误样本按PRM与ORM一致性进行排序筛选,剔除推理过程与结果矛盾的样本,避免简单加权融合的奖励冲突。
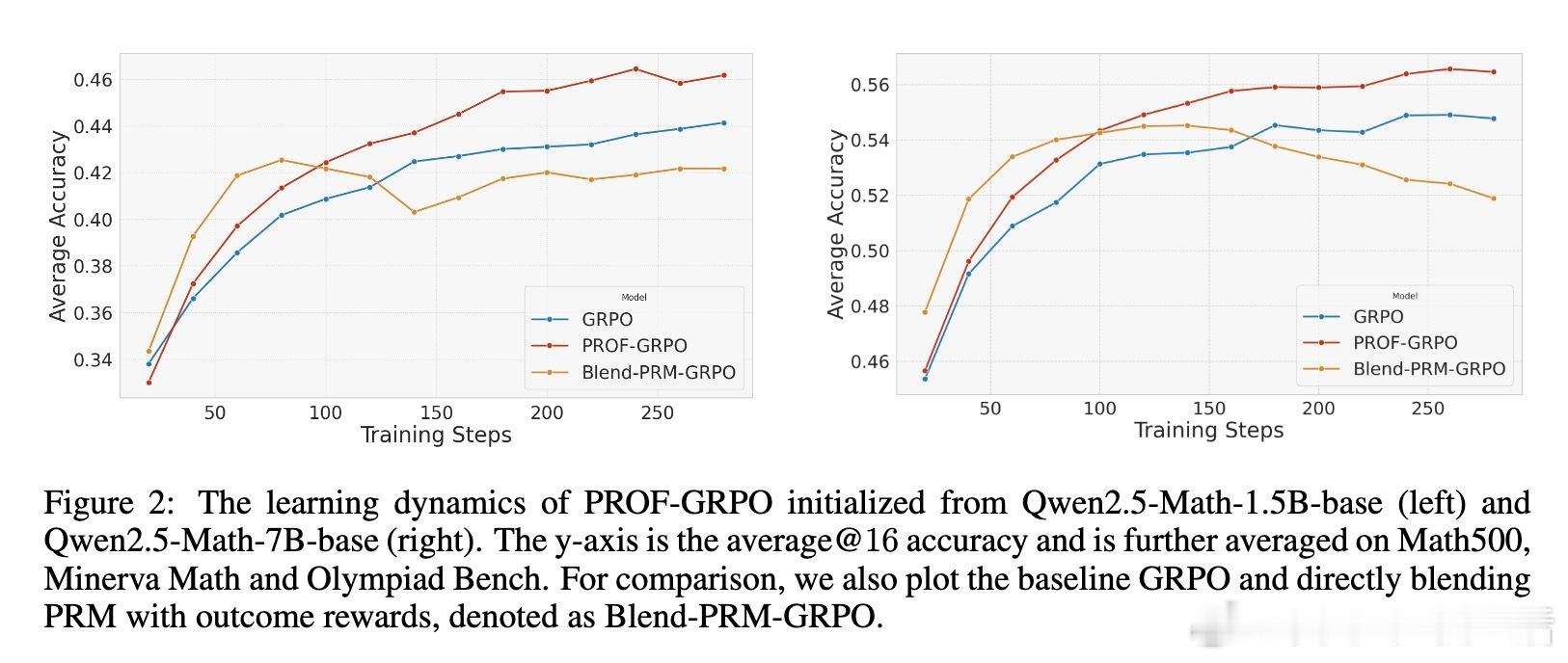
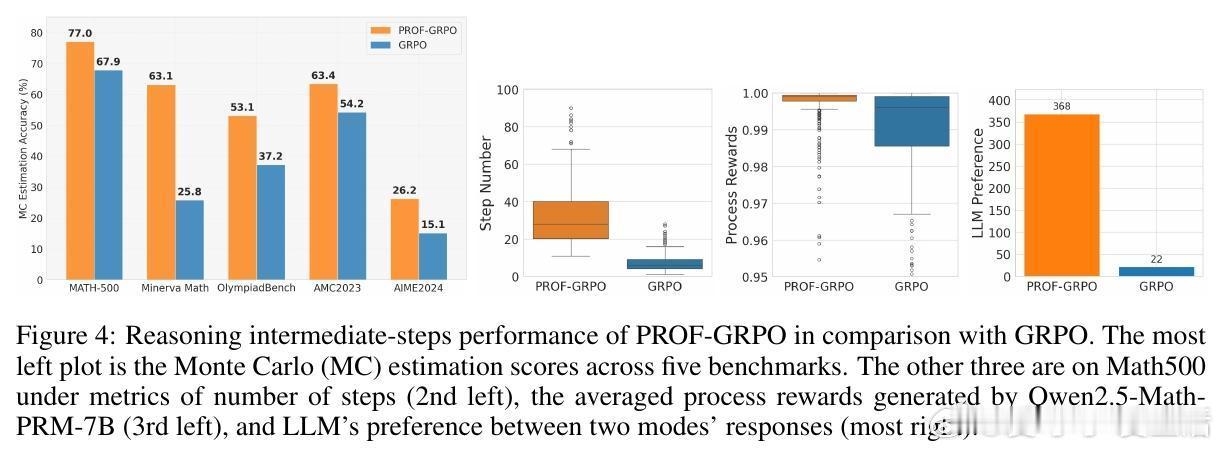
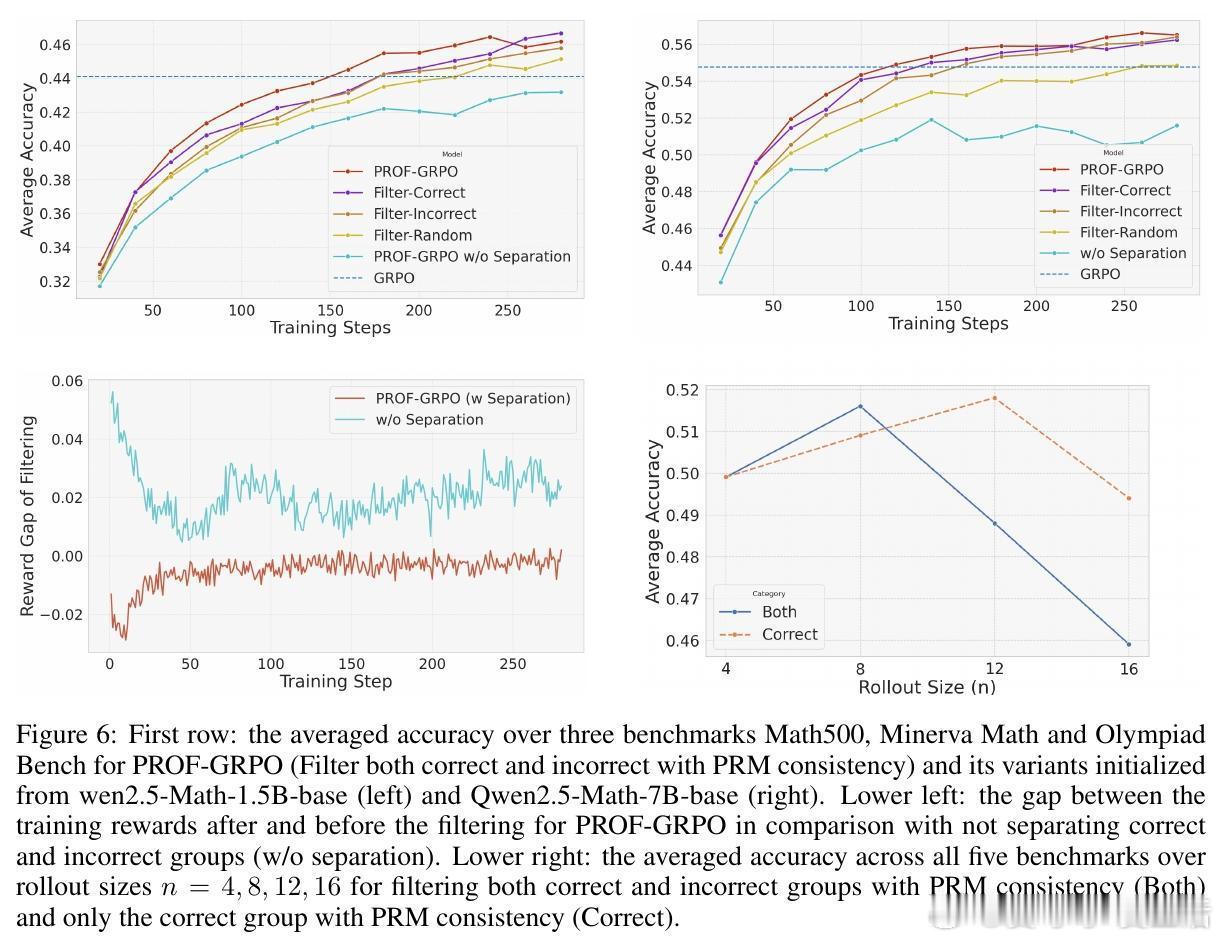
• PROF与GRPO(Group Relative Policy Optimization)结合,保障训练样本正负比例平衡,显著提高最终准确率(提升4%+)并增强中间推理步骤质量,促进模型生成更细致、易验证的推理链条。
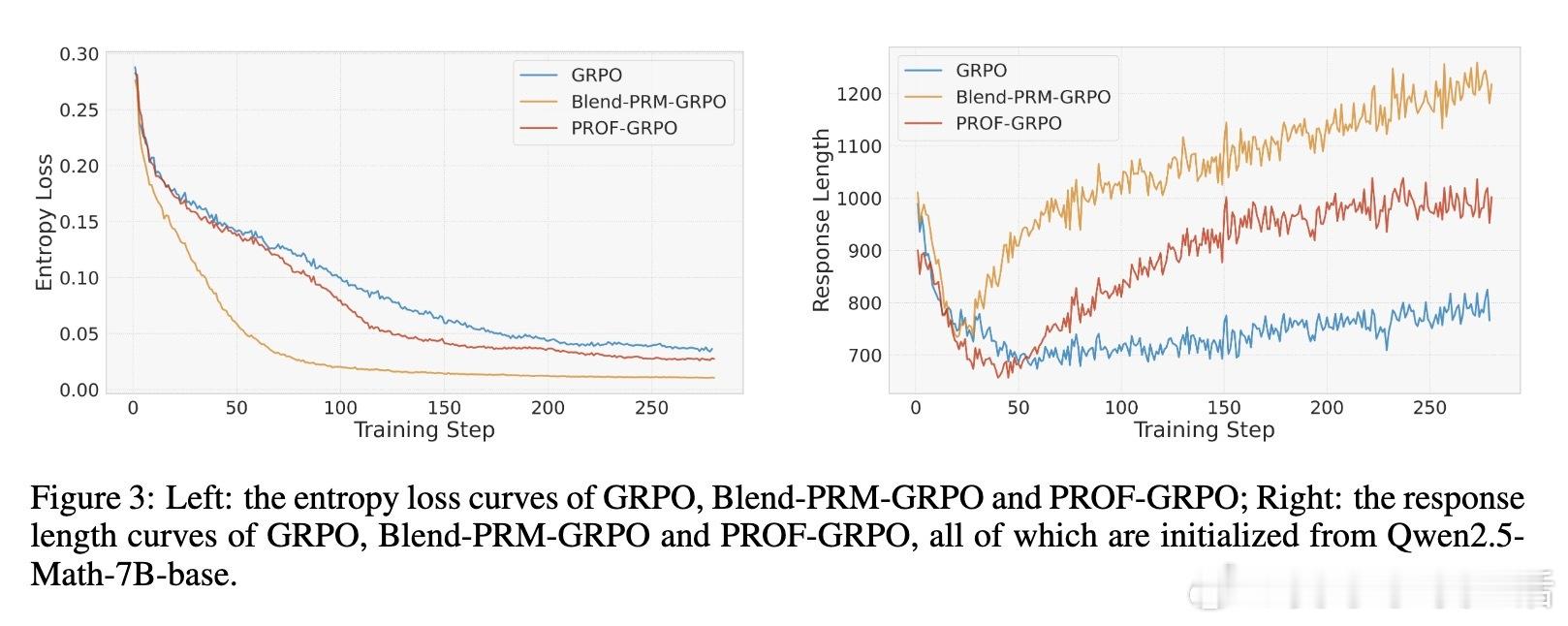
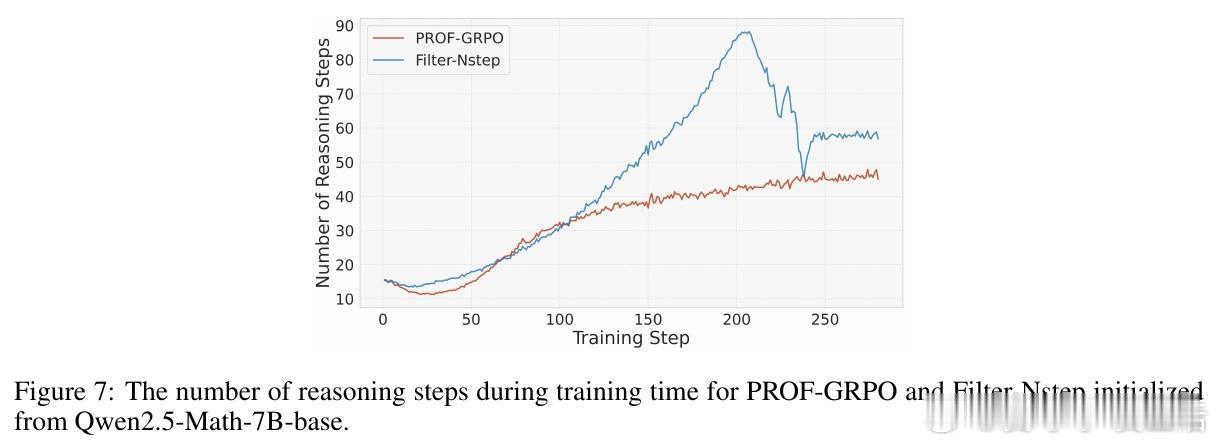
• 大规模数学推理基准测试(Math500、Minerva Math、Olympiad Bench等)展示PROF-GRPO优于纯结果奖励及简单奖励融合方法,且训练过程更稳定,避免了奖励作弊导致的熵崩溃和冗长无效推理。
• 消融研究强调分开处理正确与错误样本对过滤效果至关重要,过程奖励对正确样本的筛选贡献最大;筛选策略以平均PRM值为优,避免极端步骤评分影响。
• PROF框架不依赖特定PRM或RL算法,适配多种模型架构(Qwen、LLaMA均有验证),且具备推广到编码及网页导航等复杂推理任务的潜力。
心得:
1. 仅凭最终结果反馈训练强化学习模型存在根本局限,细粒度过程监督能显著提升推理质量。
2. 过程奖励模型虽细致但易受误判影响,巧妙过滤机制比简单奖励加权更有效避免训练偏差。
3. 样本的正负分组与比例平衡是维持训练稳定性和提升表现的关键细节,不容忽视。
详见🔗arxiv.org/abs/2509.03403
强化学习数学推理奖励建模大语言模型过程监督